Data Lakes and Analytics on AWS
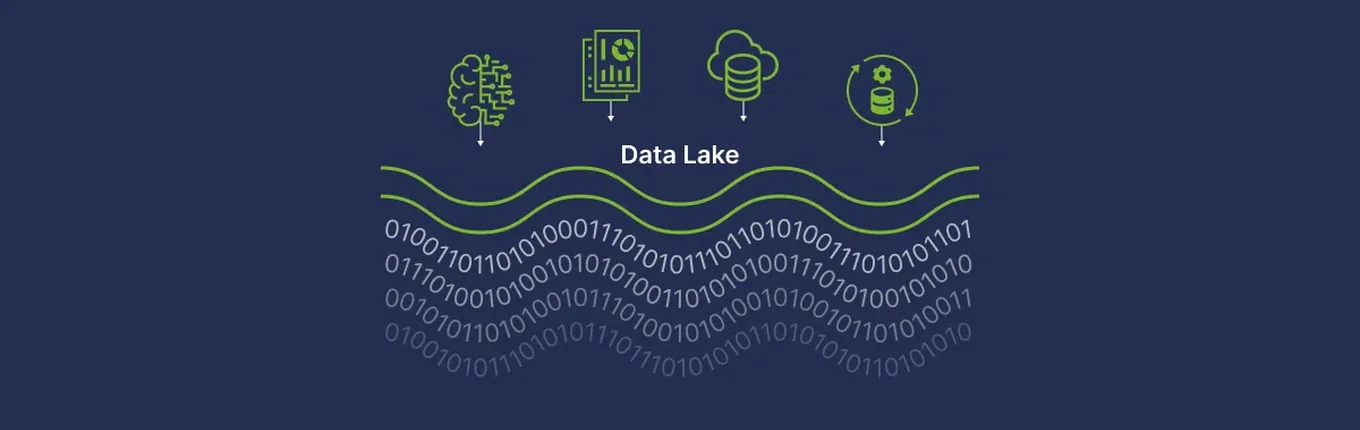
What is Data Lake? With recent technological advancements, there is a high demand for a solution for data storage and analytics that provides greater agility and flexibility than conventional data management systems.
This is where Data Lakes comes in handy for most AWS customers. Because it enables businesses to handle numerous data types from a wide range of sources and store this data, both structured and unstructured, in a centralized repository, a data lake is a novel and more common method of storing and analyzing data. You can run several sorts of analytics, from dashboards and visualizations to big data processing, real-time analytics, and machine learning to help you make better decisions, without first structuring your data. In other words, it maintains data in its original format and provides tools for analyzing, querying, and processing.
Architecture
Now lets talk about the internals of the Data Lake. The architecture is essentially a collection of tools that are used to create and operationalize such specific data approach. It starts with event processing tools, goes to ingestion, transformation pipelines and reaches the analytics and query tools. Based on business needs there are many various combinations of these tools to build a complete Data Lake. We will cover some of the possible combinations in the sections below.
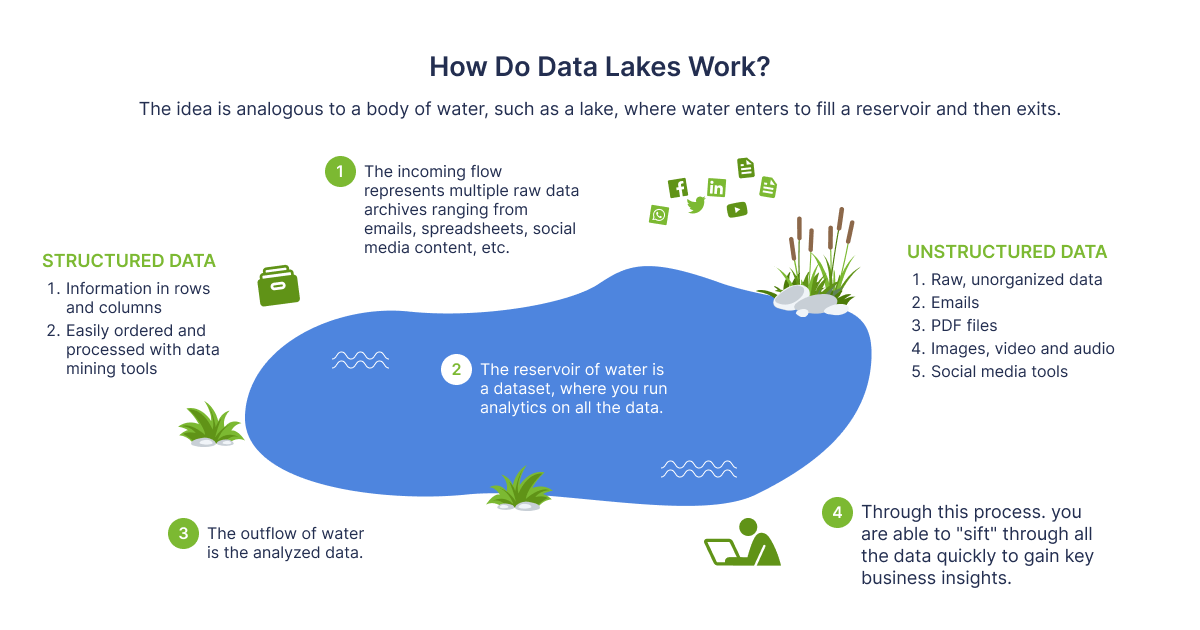
Rehan van der Merwe — “ How do Data Lakes work?”
When is comes to making the data in a lake functional you require well-defined processes for systematizing and securing that data. Lake Formation is a service comes with a set of mechanisms that help to implement governance of your data, and set up the access controls over the data lake. This feature is very essential for performing analytics and machine learning on your data.
Generally, a typical business will need both a data warehouse and a data lake, depending on the requirements, as they both fulfill various purposes and use cases. The main difference between Warehouse and the Lake is that a Data Warehouse is a database designed for the analysis of relational data from applications and transactional systems and the Data Lake as mentioned earlier holds both relational data from business applications and non-relational data from social media, IoT devices.
In Data Warehouse in order for data to serve as the “single source of truth” that consumers can rely on, information should be cleansed, enhanced, and transformed. On the other hand, in Data Lake the structure or schema of data are not specified when data is captured. This implies that all of your data may be stored without careful design. The table below represents the key differences between them.
Read also: Unleashing the Power of AI in Crafting Next-Generation Mobile Apps
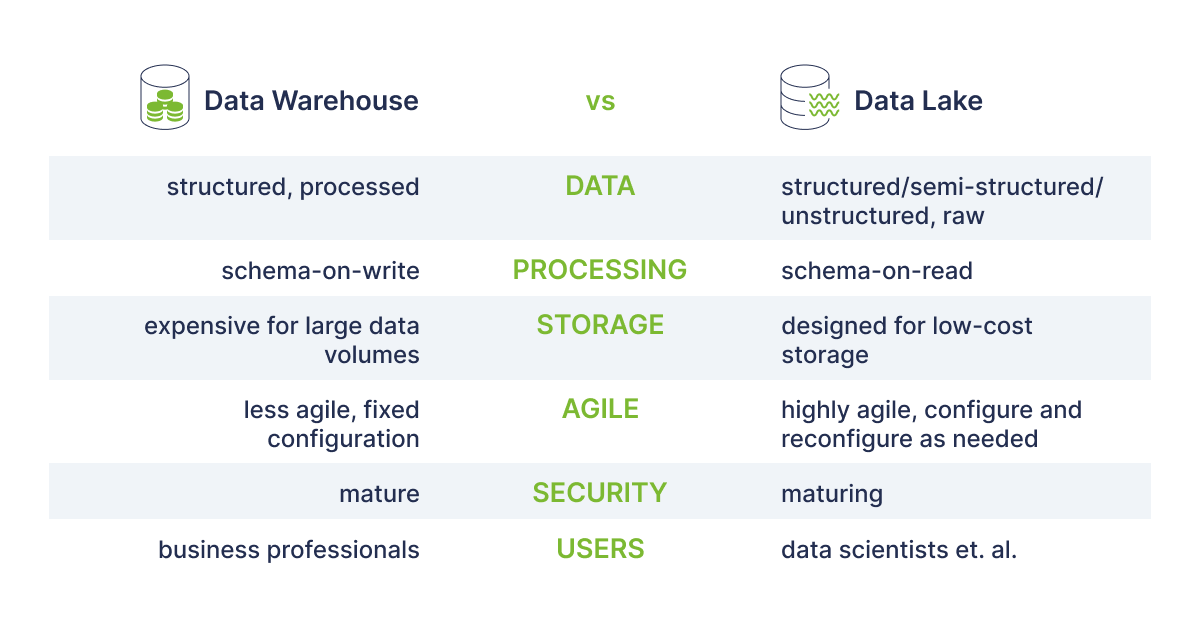
Rehan van der Merwe “Warehouse vs Lake”
Benefits & Challenges
As any other service Data Lakes on AWS has its Pros and Cons too. In this section I will try to list our the benefits and some challenges of utilizing the Data Lakes on AWS specifically.
Benefits
- Data Lakes allow you to import any amount of data that can come in real-time.
- Data Lakes perform as single source of truth for any data type. This implies the uselessness in connecting multiple sources with specific ETL tools.
- The automation at every level is the main benefit of a data lake and the infrastructure that supports it. The data set updates can technically be performed every minute and some of them can do so almost instantly in Data Lakes. Once set up, tested, and put into use, this automation changes the game. Also, it indicates that the data refresh is occurring without having an effect on the transactional systems.
- In Data Lakes the automated data load, combined with cleaning and harmonization, provides business users with insights almost immediately. Almost all teams depending on administrative policies have unlimited access to data. The majority of the time, teams have leapt over data gaps to arrive at real-time insights through visualization tools. The transactional systems can be updated with these insights to accelerate and enhance decision-making.
Challenges
Because there is no control over the raw data being stored in a data lake design, this is its fundamental drawback. A data lake must have well defined processes for cataloging and securing data in order to make the data functional otherwise it may end up to “Data Swamp”. Data lakes must include governance, semantic consistency, and access controls in order to meet the needs of more diverse audiences.
Use Cases
1. Siemens Handles 60,000 Cyber Threats per Second Using AWS Machine Learning
Siemens CDC Uses the Amazon SageMaker for data labeling, preparing and training ML algorithms. It uses Data Lake based on Amazon S3 (6 TB log per day), AWS Glue — ETL service and AWS Lambda — a serverless service that executes code in response to events. All in all, 60.000 potentially crucial events are handled every second by the serverless AWS cyber threat-analytics platform, which is created and run by a staff of fewer than a one dozen individuals.
2. Depop Goes From Data Swamp to Data Lake
Depop — social shopping application serving thousands of users (London, UK). These users engage in a variety of app-related activities, such as following, messaging, buying and selling goods, etc., which provide a steady stream of events. After making an initial attempt to replicate the data on Redshift, they rapidly came to the conclusion that performance tweaking and schema maintenance would be very time- and resource-consuming. Depop decided to use Amazon S3 as a data lake as a result. Sources to articles.
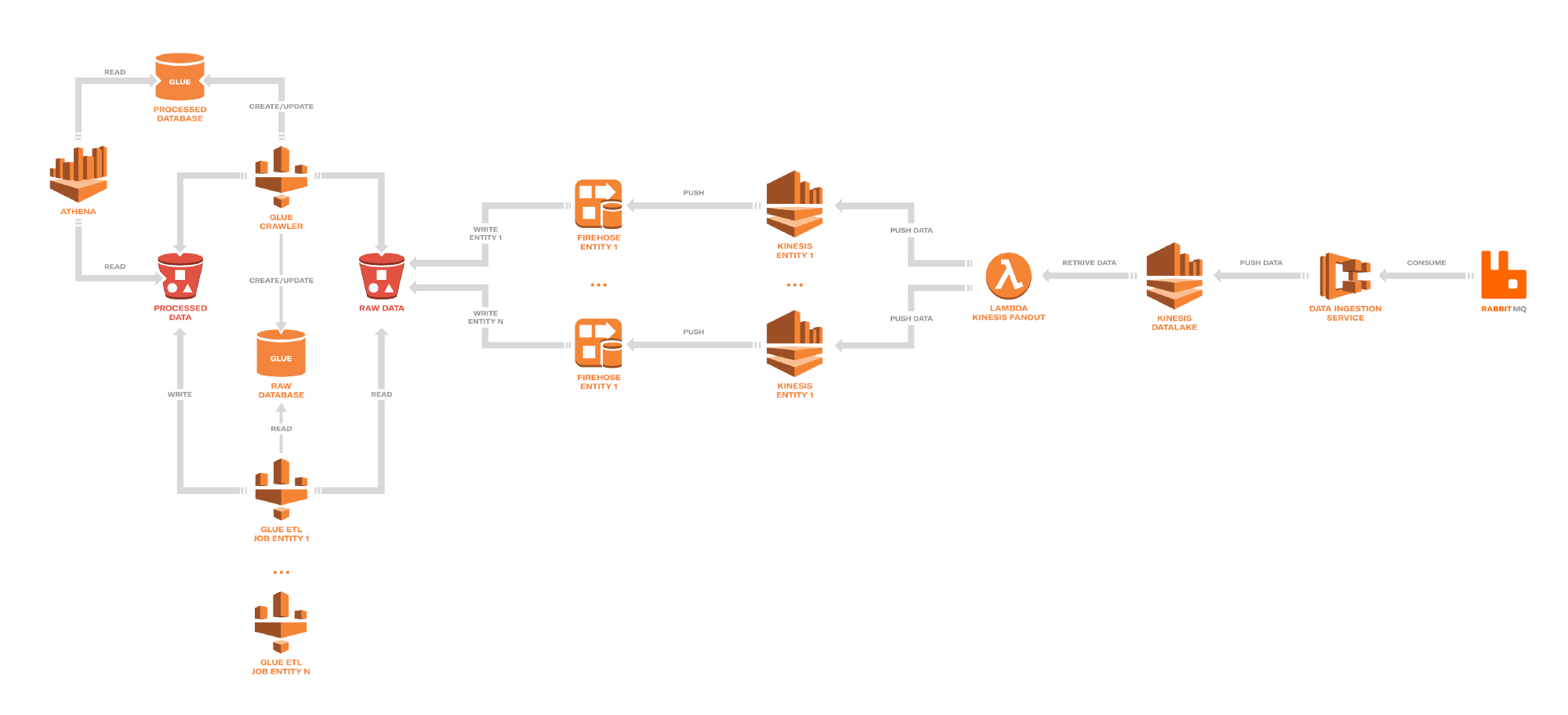
Depop Data Lake example
Depop Data Lake composition:
Ingest — > Fanout — > Transform
Software Development Hub is a team of like-minded people with extensive experience in software development, web and mobile engineering, custom enterprise software development. We create meaningful products, adhering to the business goals of the client. Main areas of development: digital health, accounting, education.
Categories
Share



Need a project estimate?
Drop us a line, and we provide you with a qualified consultation.