Databases for Your Application: Analysis of the Best Modern Solutions
Data management methods are an important factor that depends on the level of user interaction with the application. It is the speed of receiving, processing, and delivery of data, as well as the reliability of their protection, that remains the key point in the operation of a product. Therefore, the correct choice of the database determines the security of information and the comfort of using the application.
Factors of choice of database
Database stores and organizes all the data collected by a program. Convenient management is carried out with DBMS, a special software. With over 350 databases on the market, choosing the right tool is not an easy task. For the database to be useful and able to solve the tasks, consider the following factors as the sort of guidance:
- number of users who are granted simultaneous access to the program;
- what is more important — data security or program performance;
- whether scalability is being considered in the future;
- prospects of using innovative technologies in the application, such as machine learning or artificial intelligence;
- the need to integrate other solutions — business intelligence tools;
- some other requirements for the database, etc.
Characteristics of more than 360 databases in detail are available here: the rating includes relational DBMS, key-value stores, document stores, DBMS time series, search engines, object-oriented, etc.
Types of databases
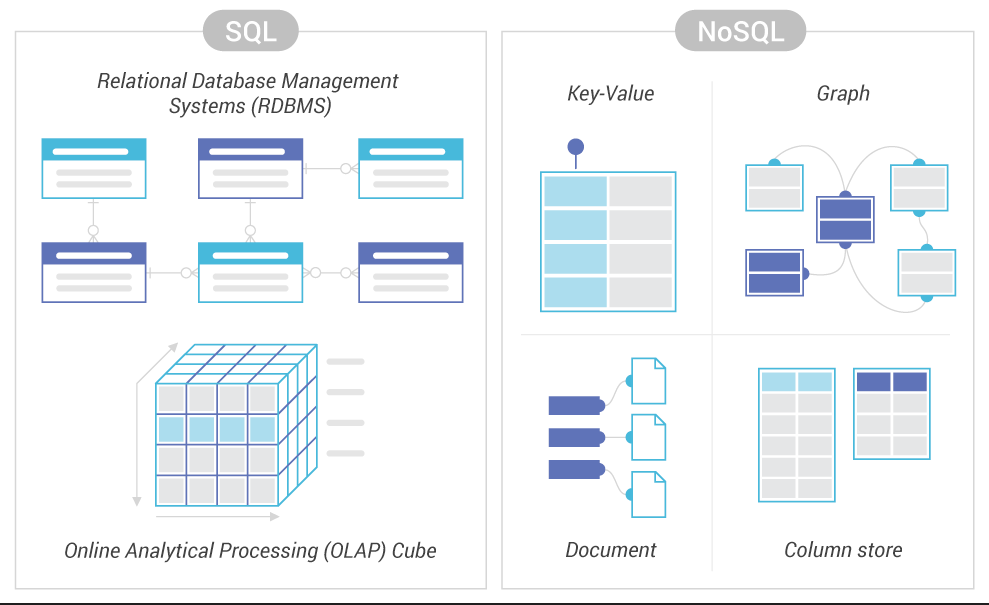
All databases can be divided into two large groups: SQL-Based and NoSQL-Based, i.e. relational and non-relational. The difference lies in the design structure, supported data types, and storage method. More details about it are below.
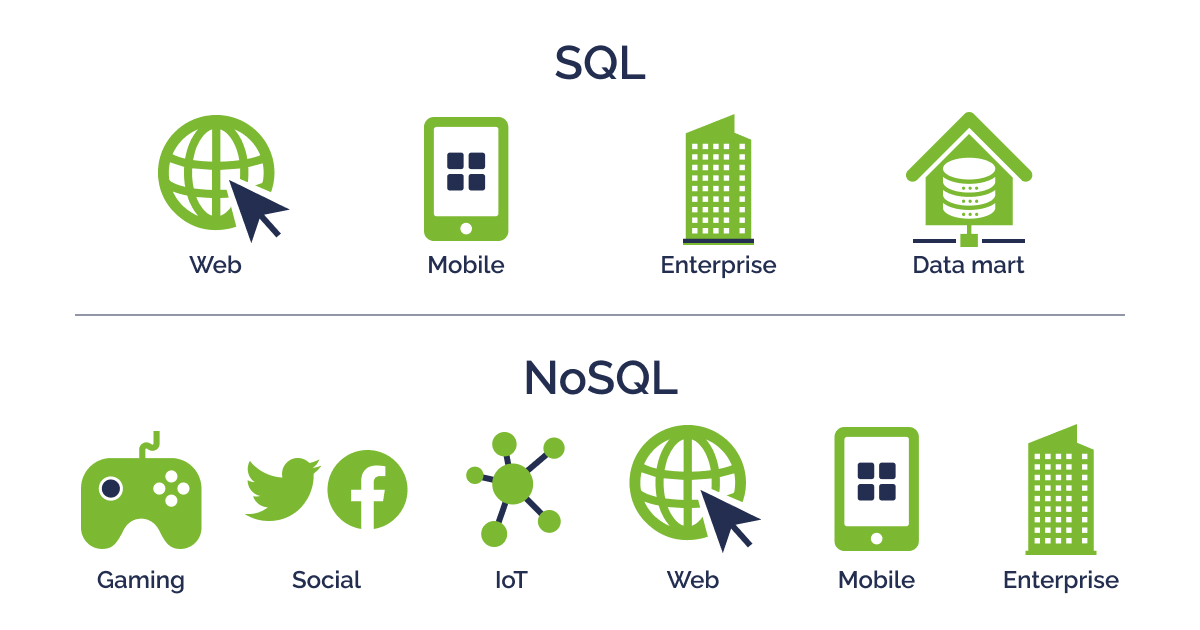
SQL databases
A relational database is a set of tables with predefined relationships. This type of database is used most frequently: for support and queries, the SQL structured query language is used. What are the advantages of this category of DBMS?
- The best option for storing structured data. Zip codes, credit card numbers, dates, identification numbers, and other data types are easily accessed using SQL DB. A high level of documentation, support, and compatibility with most modern frameworks and libraries are preserved.
- Safety. Support of access rights provided by relational databases with the ability to read and edit data and controllability of privileged rights protect information from the risk of data theft by third parties.
The key feature of SQL database is its compliance with the concept of ACID, which includes the parameters of atomicity, consistency, isolation, and durability. The main thing is that ACID eliminates the possibility of two transactions overlapping, namely:
- Atomicity allows each transaction to be viewed as a unit. If the set of operations is unsuccessful, no money will be withdrawn;
- Consistency involves entering data into the database that meets all the rules. If the data is not recognized as real, a return occurs. Accordingly, harm in an illegal transaction is excluded;
- Isolation, when a transaction guarantees safe processing of data;
- Reliability means confidential information storage, even if the transaction was unsuccessful or there was a system failure.
Compliance of the database with all these requirements determines its use for storing financial, medical, and personal data. Such databases are suitable, for example, for medical information systems.
Though there are some disadvantages of SQL databases:
- Lack of flexibility. It is more difficult to operate with semi-structured or unstructured data. Therefore, heavy loads and the scope of the Internet of Things analytics are contraindications for installing SQL-Based;
- The structure's complication negatively affects the data exchange between large software solutions. In this regard, they often resort to the use of autonomous relational databases when it comes to several departments of one large project;
- Operating on one server forces the user to purchase expensive server hardware.
One of the best SQL is the PostgreSQL database, with its stability and safety. PostgreSQL is ACID compliant. The SDH team often uses this database to develop web and mobile applications.
NoSQL-Based databases
NoSQL-Based are non-relational or distributed databases. This type of database was created as an alternative to relational databases with their shortcomings. More flexible and scalable programs are adapted to storing and processing unstructured data (information from social networks, photos, MP3 files), changing them without affecting existing information. Such databases can run on multiple servers, which simplifies and reduces the cost of scaling compared to SQL.
What attracts to NoSQL-Based databases is their fault tolerance. Hosting on multiple servers means that the failure of one component will not bring down the entire system. At the same time, the technology is less mature than SQL and less consistent with the ACID principle.
Conventionally, all non-relational databases are divided into 4 groups:
- Key-value stores are the simplest type of database with the ability to store key values and standard functions to get the result. This includes the Redis database. The simple structure provides scalability, mostly horizontal when the number of computing equipment increases for expansion. The database is used for key-caching data, storing comments, reviews, user profiles, etc. Though the simplicity of the database sometimes turns into a disadvantage: here, it will not be possible to perform operations available in other databases. That is why the key-value store is often used in combination with other types of databases;
- Document storage. Documentation-oriented databases store data in a single BSON, JSON, or XML file. Documents of the same type are grouped into collections and lists. The model of such a database is visually similar to a tree or forest, where the root element is associated with one or more leaf elements. Document stores are organized into collections of documents, although managing large systems can become even more complex. An important advantage of document repositories is their flexibility which allows you to manage content, quickly create prototypes and analyze data. A bright example is MongoDB, which is also often used by SDH;
- Column storage. Each column acts as a logical database array in a database, so the system is easily scalable and duplicated. The column storage is suitable for working with structured columns and unstructured ones, which makes it easier to analyze them. The processing of analytical operations is successful here, while transactions are processed worse;
- Graph storage. In a graph store, each isolated data document is a node. In most databases, it is possible to perform node-searching functions. Systems are optimized for projects with graph data structures like social networks.
When choosing a database, it is important to trust the contractor who will suggest the best option, taking into account the specific features of the product.
Categories
About the author

Lead DevOps Engineer at Software Development Hub with over 18 years of experience in Linux-based systems and cloud resource automation. Adept at designing, implementing, and optimizing deployment processes to ensure seamless operations and high system performance.
Share



Need a project estimate?
Drop us a line, and we provide you with a qualified consultation.