1. Simple RAG (for Small E-commerce)
What is Simple RAG
Simple RAG Use Cases in E-commerce
Simple RAG Pros and Cons
2. Simple RAG with Memory (for Customer Support Chatbot)
What is Simple RAG with Memory
Customer Support Use Cases
Simple RAG with Memory Pros and Cons
3. Branched RAG (for Legal Applications)
What is Branched RAG
Legal Domain Use Cases
Branched RAG Pros and Cons
4. HyDE (for SaaS & Tech R&D)
What is HyDE RAG
SaaS and R&D Use Cases
HyDE RAG Pros and Cons
5. Adaptive RAG (for E-commerce)
What is Adaptive RAG
E-commerce Use Cases
Adaptive RAG Pros and Cons
6. Corrective RAG (CRAG) (for Healthcare)
What is Corrective RAG (CRAG)
Healthcare Use Cases
CRAG Pros and Cons
7. Self-RAG (for Education & Research)
What is Self-RAG
Education and Research Use Cases
Self-RAG Pros and Cons
8. Agentic RAG (for Finance)
What is Agentic RAG
Finance Use Cases
Agentic RAG Pros and Cons
Implementation Strategy and Future Outlook
8 RAG Architecture Diagrams You Need to Master in 2025
Retrieval Augmented Generation (RAG) architecture addresses one of the most persistent challenges in AI implementation: the generation of inaccurate or fabricated information, commonly known as hallucinations. This architectural approach combines real-time data retrieval with text generation capabilities, creating a system that grounds responses in verifiable sources rather than relying solely on pre-trained model knowledge.
RAG systems have evolved considerably from basic implementations to sophisticated frameworks that serve specific business requirements. The architecture actively searches external knowledge sources—PDFs, databases, web pages, and proprietary documents—to provide current information that maintains relevance to user queries. This retrieval-generation combination ensures that responses remain anchored in domain-specific knowledge while preserving the natural language capabilities that make large language models valuable for business applications.
Why should technical teams prioritize understanding RAG architecture variations? The answer lies in the diverse requirements across industries and use cases. We have identified eight distinct RAG architectures that address specific operational challenges: Simple RAG, Simple RAG with Memory, Branched RAG, HyDE, Adaptive RAG, Corrective RAG, Self-RAG, and Agentic RAG. Each architecture employs different approaches to document retrieval, response generation, and context management, making them suitable for particular industry applications.
1. Simple RAG (for Small E-commerce)
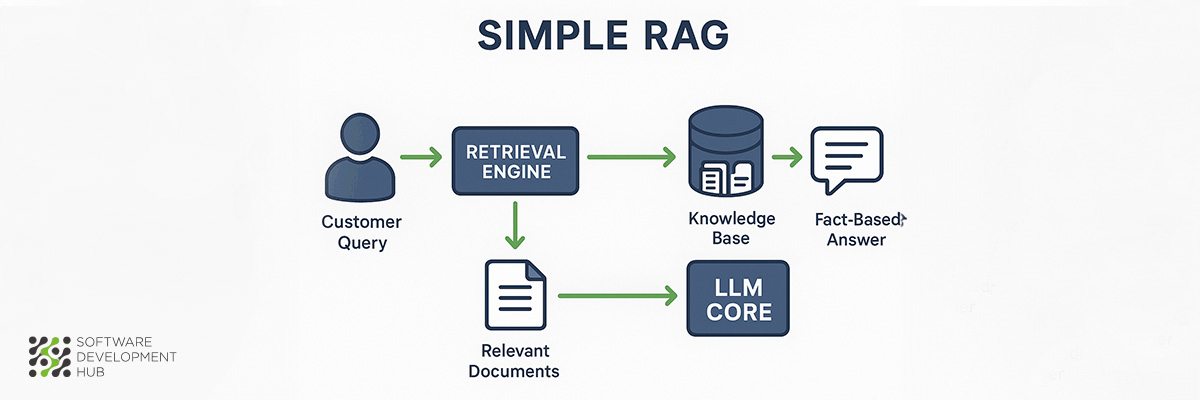 Simple RAG architecture serves as the foundation for retrieval augmented generation systems, particularly suited for small e-commerce businesses that need to improve customer interactions without extensive technical infrastructure investments.
Simple RAG architecture serves as the foundation for retrieval augmented generation systems, particularly suited for small e-commerce businesses that need to improve customer interactions without extensive technical infrastructure investments.
What is Simple RAG
Simple RAG components function through a two-part system that combines retrieval capabilities with generative language processing. The architecture connects a document retrieval system directly to a language model, creating a hybrid approach that draws from both pre-trained knowledge and current data sources. Traditional language models operate within the constraints of their training data, but Simple RAG extends this capability by accessing external information repositories in real-time.
Small e-commerce operations find this architecture particularly valuable because it requires minimal technical expertise while delivering substantial improvements in customer service quality. The system bridges the gap between static model knowledge and dynamic business information by accessing product databases, inventory systems, and customer documentation as needed.
Simple RAG Use Cases in E-commerce
E-commerce businesses can implement Simple RAG across several operational areas:
- Product recommendations: The system analyzes customer purchase history and current inventory to suggest relevant products based on real-time data rather than generic recommendations.
- Inventory management: Automated systems can process sales patterns and stock levels to generate reorder alerts and prevent stockouts that impact customer satisfaction.
- Search enhancement: RAG-enabled search functionality interprets customer intent and product specifications to deliver more precise search results.
- Customer support: Chatbots access product databases directly to answer specific questions about features, availability, and compatibility, reducing response times significantly.
Simple RAG Pros and Cons
Pros:
- Enhanced accuracy: Responses draw from curated business data, ensuring factual consistency and relevance to current operations.
- Real-time information: The system accesses current inventory, pricing, and policy information without requiring model retraining.
- Domain specialization: Product-specific queries receive accurate answers by retrieving information from specialized knowledge bases rather than general training data.
- Adaptability: Organizations can modify retrieval sources and generator parameters independently to match changing business requirements.
Cons:
- Data quality dependence: System accuracy depends entirely on the quality and currency of source documents, making data maintenance critical.
- System complexity: Implementation requires integrating multiple components, increasing technical complexity compared to standalone language models.
- Increased latency: The two-step retrieval and generation process introduces delays compared to direct model responses.
- Data security concerns: Access to business databases and customer information requires robust security measures to protect sensitive data.
Small e-commerce businesses with limited technical teams can use Simple RAG to enhance customer experiences without the complexity and cost associated with more sophisticated AI architectures.
2. Simple RAG with Memory (for Customer Support Chatbot)
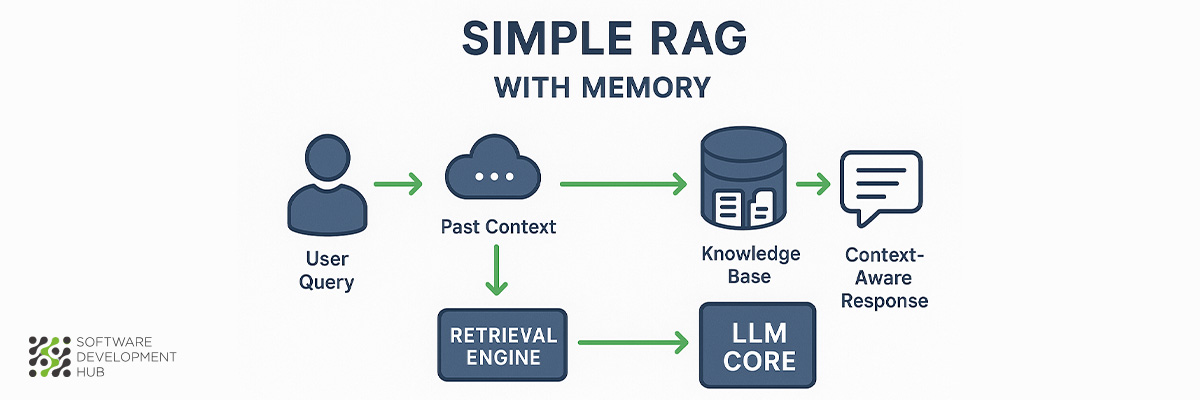 Traditional retrieval systems face a fundamental limitation in customer service applications: the inability to maintain context across conversations. Memory-enhanced RAG architectures address this constraint by introducing conversational continuity, creating more sophisticated customer-facing AI applications.
Traditional retrieval systems face a fundamental limitation in customer service applications: the inability to maintain context across conversations. Memory-enhanced RAG architectures address this constraint by introducing conversational continuity, creating more sophisticated customer-facing AI applications.
What is Simple RAG with Memory
Simple RAG with Memory extends the basic RAG framework by incorporating conversation history storage and retrieval mechanisms. The architecture stores key elements from previous interactions and integrates this contextual information with incoming queries. This approach eliminates the "conversational amnesia" that plagues standard RAG implementations, where each customer interaction starts from zero context.
The system maintains a memory store that captures relevant details from past exchanges—customer preferences, previous issues, resolution attempts, and contextual information that influences current requests. This capability enables the chatbot to reference earlier conversations naturally, creating continuity that mirrors human customer service interactions.
Customer Support Use Cases
Memory-enhanced RAG architecture proves particularly valuable in several customer service scenarios:
- Ongoing issue resolution: The system recalls previous complaints about delayed shipments or defective products, automatically connecting new inquiries to existing cases without requiring customers to re-explain their situations.
- Personalized assistance: The chatbot accesses conversation history to provide recommendations based on previously discussed preferences and purchase patterns.
- Multi-step troubleshooting: Complex technical issues often require multiple interactions to resolve. Memory enables logical progression through troubleshooting steps without starting over. HTEC's implementation reduced average resolution times from days to hours.
- Order tracking and updates: Customer service interactions frequently involve order status inquiries. The system maintains context about specific orders and concerns throughout multiple touchpoints.
Customer adoption data supports the effectiveness of these systems. US consumers using AI-based chatbot services 42% more during the 2024 holiday season compared to the previous year, with 80% reporting positive experiences with AI-powered customer service.
Simple RAG with Memory Pros and Cons
Pros:
- Reduced repetition: Customers avoid restating problems in subsequent messages.
- Human-like interactions: Conversation flow mirrors natural human dialogue patterns.
- Personalized responses: The system tailors answers using historical interaction data.
- Improved contextual understanding: Follow-up questions referencing earlier topics receive appropriate responses.
Cons:
- Higher processing costs: Memory storage and retrieval operations increase computational overhead.
- Data privacy concerns: Conversation history storage requires careful consideration of user privacy and data protection regulations.
- Risk of outdated information: The system may reference previously stored information that no longer applies.
- Memory management challenges: Excessive memory can confuse the model without proper contextual chunking strategies.
Customer support teams implementing memory-enhanced RAG must balance these trade-offs while designing systems that improve user experience without introducing unacceptable risks or costs.
3. Branched RAG (for Legal Applications)
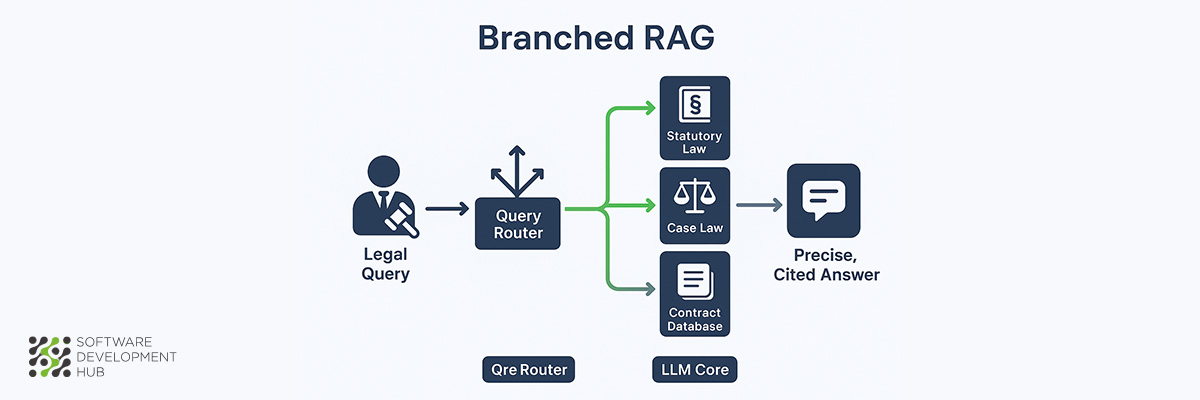 Legal professionals require access to vast repositories of case law, statutes, regulations, and precedents—often simultaneously. Branched RAG architecture addresses this challenge through intelligent query routing that directs searches to the most relevant information sources, making it particularly suited for legal applications.
Legal professionals require access to vast repositories of case law, statutes, regulations, and precedents—often simultaneously. Branched RAG architecture addresses this challenge through intelligent query routing that directs searches to the most relevant information sources, making it particularly suited for legal applications.
What is Branched RAG
Branched RAG evaluates incoming queries and selectively retrieves information from the most appropriate data sources rather than conducting broad searches across all available repositories. This targeted approach improves both efficiency and accuracy by determining which specific legal databases should be queried based on the nature of the legal question.
The architecture differs fundamentally from standard RAG implementations that query all available sources indiscriminately. Branched RAG first analyzes the query to identify its legal domain—whether it involves contract law, tort law, criminal statutes, or regulatory compliance—then directs the search to specialized repositories most likely to contain relevant authorities. This approach prevents the system from being overwhelmed with irrelevant data while ensuring comprehensive coverage of pertinent legal sources.
Legal queries often involve multiple dimensions requiring different types of authorities. Branched RAG excels at decomposing complex legal questions into manageable components, allowing for targeted retrieval that addresses each aspect with appropriate legal sources. This capability proves essential when handling questions that span different areas of law or require reference to various jurisdictional authorities.
Legal Domain Use Cases
Legal practice environments benefit from Branched RAG architecture across several specialized applications:
- Legal Research and Case Analysis: The system identifies connections among cases, statutes, and precedents, revealing patterns in judicial reasoning and predicting potential legal outcomes based on historical trends
- eDiscovery Optimization: Branched RAG automates document retrieval and analysis during litigation, significantly reducing the time required for document review processes while improving accuracy in identifying relevant materials
- Compliance Audits: Organizations use the architecture to verify adherence to regulatory requirements by automatically retrieving and analyzing relevant legal standards, streamlining the traditionally labor-intensive process of compliance verification
- Contract Analysis: Legal teams can efficiently search and summarize internal counsel advice and precedent guidance, building on previous work to maintain consistency in legal positions
Recent developments include specialized benchmarks like LegalBench-RAG, which evaluate retrieval components specifically for legal applications, providing frameworks to assess how effectively these systems locate precise legal references.
Branched RAG Pros and Cons
Advantages:
- Effectively manages open-ended legal questions requiring multiple areas of expertise
- Improves precision by routing queries to appropriate legal authorities while reducing irrelevant results
- Minimizes risk of overlooking critical aspects of complex legal issues
- Enhances accuracy through targeted retrieval from specialized legal databases
Limitations:
- Requires sophisticated coordination mechanisms to synthesize findings from different legal sources
- Demands advanced query analysis capabilities to properly categorize legal questions
- Implementation complexity increases due to multiple retrieval pathways and legal domain requirements
- Risk of information overload if filtering mechanisms are not properly configured
For legal applications requiring precision, comprehensive analysis, and navigation of complex authority structures, Branched RAG provides a framework that mirrors how experienced legal professionals approach research—systematically, thoroughly, and with attention to jurisdictional and domain-specific requirements.
4. HyDE (for SaaS & Tech R&D)
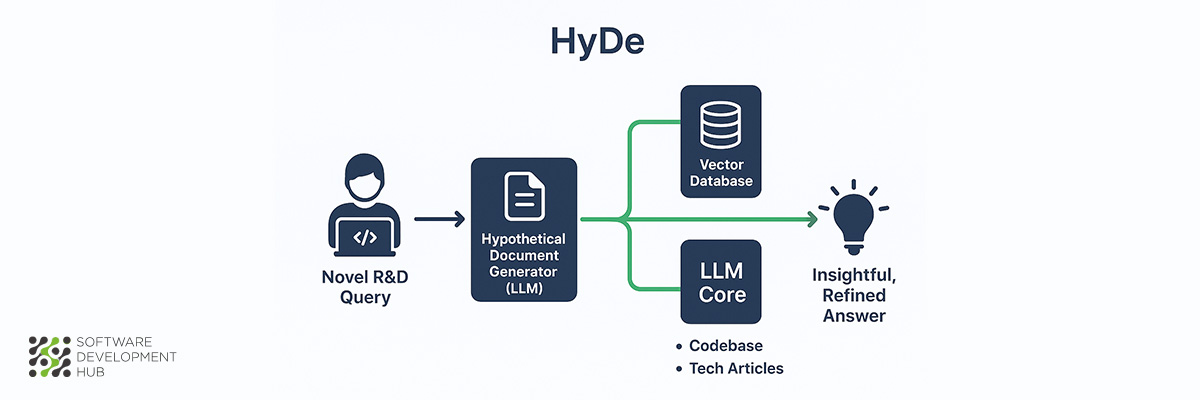 HyDE (Hypothetical Document Embeddings) addresses a persistent limitation in information retrieval: the semantic gap between user queries and available documentation. This architecture generates synthetic documents to improve matching accuracy, proving especially effective in SaaS platforms and technology R&D environments where technical precision matters.
HyDE (Hypothetical Document Embeddings) addresses a persistent limitation in information retrieval: the semantic gap between user queries and available documentation. This architecture generates synthetic documents to improve matching accuracy, proving especially effective in SaaS platforms and technology R&D environments where technical precision matters.
What is HyDE RAG
HyDE RAG employs an unconventional approach that creates "hypothetical" documents to enhance retrieval accuracy. Rather than matching queries directly to existing documents, HyDE first generates a synthetic answer using a language model. This hypothetical document captures the query's intent and context, even when the generated content contains factual inaccuracies.
The architecture then converts this synthetic document into vector embeddings, positioning them within the same vector space as real documents. This process enables similarity searches based on answer-to-answer relationships instead of traditional query-to-answer matching. The result is improved retrieval performance, particularly when user queries contain limited keywords or use terminology that differs from source documentation.
SaaS and R&D Use Cases
Technology companies have found HyDE particularly valuable for several applications:
- Developer question answering: HyDE demonstrates superior performance compared to zero-shot baselines for technical developer queries, achieving higher scores across helpfulness, correctness, and detail metrics
- Technical documentation search: The architecture excels at locating relevant documentation even when user queries employ non-standard technical terminology
- Code retrieval: One implementation created a retrieval corpus containing over 3 million Java and Python Stack Overflow posts with accepted answers, showcasing HyDE's effectiveness for programming solution retrieval
- Research synthesis: R&D teams utilize HyDE to connect disparate research findings through conceptual similarities rather than keyword matching
HyDE RAG Pros and Cons
Advantages:
- Zero-shot retrieval: Functions effectively without requiring relevant labels or dataset-specific training
- Cross-lingual capabilities: Maintains performance across multiple languages, supporting global technology organizations
- Semantic understanding: Captures relevance essence despite terminology variations
- Enhanced retrieval quality: Consistently outperforms classical BM25 and unsupervised contrastive retrieval methods
Limitations:
- Knowledge bottleneck: HyDE-generated documents may contain factual errors that affect retrieval accuracy
- Increased latency: Additional hypothetical document generation introduces computational overhead and response delays
- Novel topic limitations: May struggle with subjects completely unfamiliar to the underlying language model
- Resource intensity: Requires greater LLM usage compared to traditional RAG approaches
SaaS companies and research organizations continue adopting HyDE architecture despite these constraints, particularly when seeking sophisticated retrieval mechanisms for technical content management.
5. Adaptive RAG (for E-commerce)
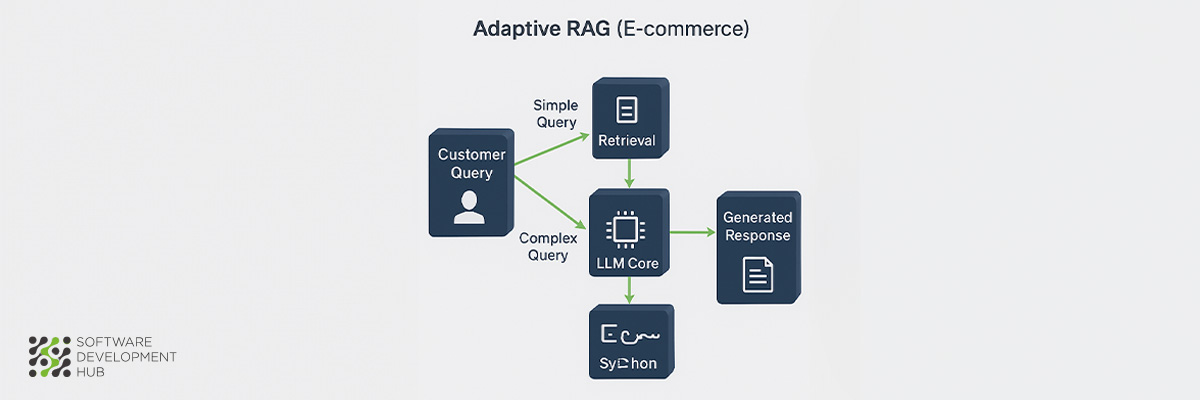 E-commerce platforms face constant pressure to balance computational resources with response accuracy. Adaptive RAG architecture addresses this challenge through intelligent query complexity assessment, automatically selecting the most efficient retrieval strategy for each customer interaction.
E-commerce platforms face constant pressure to balance computational resources with response accuracy. Adaptive RAG architecture addresses this challenge through intelligent query complexity assessment, automatically selecting the most efficient retrieval strategy for each customer interaction.
What is Adaptive RAG
Adaptive RAG employs dynamic strategy selection based on query complexity analysis, distinguishing it from fixed RAG implementations that apply uniform retrieval approaches regardless of question difficulty. The architecture evaluates incoming queries and seamlessly transitions between retrieval methods—ranging from direct language model responses for simple product questions to multi-step retrieval processes for complex shopping scenarios. This selective approach prevents resource waste on straightforward queries while ensuring adequate processing power for sophisticated customer requests.
The architecture's core innovation lies in its query complexity classifier, which determines the optimal response strategy and enables the system to reduce RAG costs by up to 4x while maintaining response accuracy. For simple product availability questions, the system bypasses retrieval entirely, whereas complex comparison requests trigger expanded context gathering through progressive document retrieval.
E-commerce Use Cases
Retail applications benefit significantly from Adaptive RAG's selective resource allocation:
Personalized shopping experiences emerge through tailored product recommendations that analyze user interaction patterns alongside real-time inventory data. Inventory management capabilities help optimize stock levels by processing sales trends, customer behavior patterns, and seasonal demand fluctuations. Customer support systems efficiently handle both basic product inquiries and complex troubleshooting requests without uniform resource consumption. Dynamic pricing strategies benefit from selective market data retrieval that matches information gathering intensity to pricing decision complexity.
Adaptive RAG Pros and Cons
The architecture delivers measurable computational cost reductions—up to 4x savings according to recent implementations. Efficiency improvements occur without accuracy degradation, and the system effectively balances response time, quality, and resource consumption. Query complexity variation handling prevents simple requests from triggering unnecessary processing overhead.
However, implementation requires accurate query complexity classification capabilities. The architecture introduces greater complexity compared to standard RAG approaches. Classifier processing may add slight latency, and misclassification risks can lead to suboptimal resource allocation for specific queries.
Adaptive RAG represents a significant advancement for e-commerce platforms where operational efficiency and cost management directly impact business sustainability and customer experience quality.
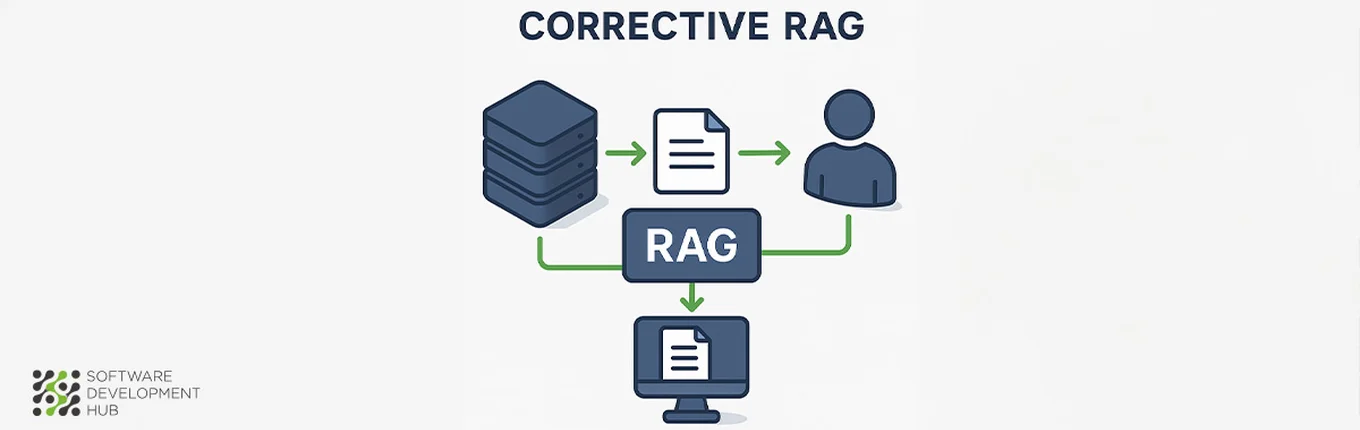
6. Corrective RAG (CRAG) (for Healthcare)
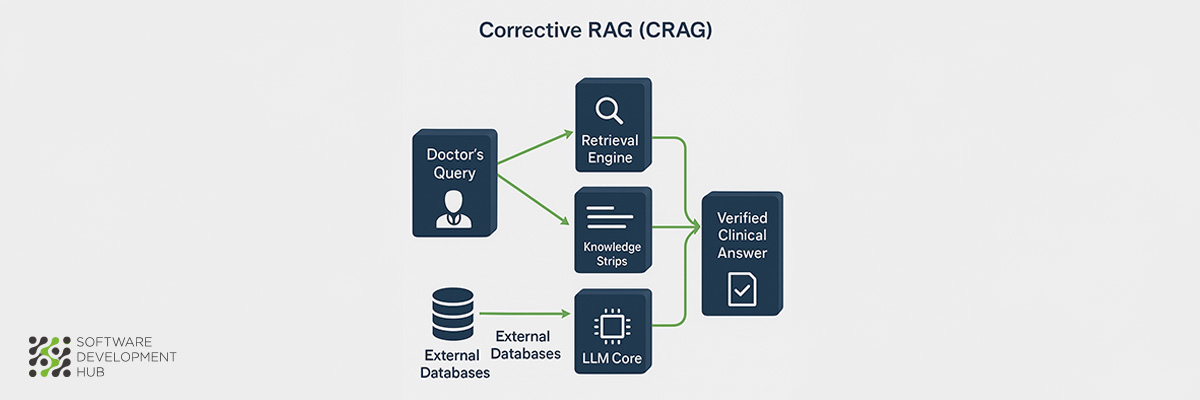 Healthcare applications demand exceptional accuracy standards where AI errors can directly impact patient safety and clinical outcomes. Corrective RAG (CRAG) architecture addresses these critical requirements through systematic error-checking mechanisms that substantially reduce hallucination risks in medical AI systems.
Healthcare applications demand exceptional accuracy standards where AI errors can directly impact patient safety and clinical outcomes. Corrective RAG (CRAG) architecture addresses these critical requirements through systematic error-checking mechanisms that substantially reduce hallucination risks in medical AI systems.
What is Corrective RAG (CRAG)
Corrective RAG represents a sophisticated evolution of standard RAG frameworks, specifically engineered to enhance accuracy and reliability in AI-generated medical responses. The architecture differs from conventional RAG systems by incorporating self-correction mechanisms with iterative feedback loops that continuously evaluate and refine outputs. This self-corrective approach ensures superior factual consistency and minimizes hallucinations—requirements that are non-negotiable in healthcare environments where inaccurate information can lead to serious patient consequences.
The fundamental principle behind CRAG involves aligning AI system responses with verified medical sources while maintaining rigorous error reduction protocols. This approach becomes particularly valuable in clinical settings where precision directly correlates with patient safety outcomes.
Healthcare Use Cases
Clinical implementations of CRAG architecture demonstrate measurable effectiveness in real-world medical applications:
Diagnostic support systems utilizing CRAG can cross-reference symptom presentations against current medical guidelines, preventing the recommendation of outdated or contraindicated treatments. Research institutions including Mayo Clinic are actively exploring similar architectures to enhance clinical decision-making processes.
A particularly noteworthy study involving RAG-enhanced models for iodinated contrast media consultation achieved complete hallucination elimination, reducing error incidence from 8% to 0%. This represents a significant improvement over previous medical-specialized models that reported hallucination rates between 28.6-39.6%.
CRAG Pros and Cons
Advantages:
- Substantial accuracy improvements through self-correction mechanisms effectively reduce medical hallucinations
- Enhanced clinical reliability by aligning responses with verified medical sources
- Superior patient privacy protection through local deployment frameworks compliant with HIPAA and GDPR regulations
- Reduced response latency compared to cloud-based LLMs, enabling real-time clinical applications
Limitations:
- Implementation complexity requires careful configuration of medical feedback loops
- Potential overcorrection may filter valid but atypical medical scenarios
- Continuous updating requirements for evolving medical knowledge bases
- Clinical judgment oversight remains essential from qualified medical professionals
CRAG architecture provides a robust solution for healthcare organizations seeking to balance the competing demands of AI accuracy, regulatory compliance, and patient safety requirements.
7. Self-RAG (for Education & Research)
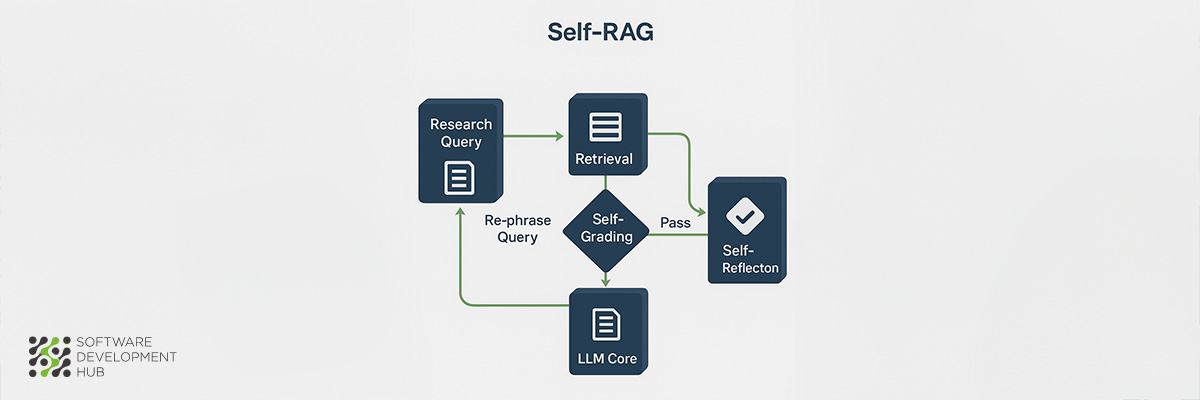 Academic institutions face mounting pressure to ensure information reliability and maintain research integrity. Self-RAG introduces a novel approach where AI systems develop the capability to critically evaluate their own outputs, making it particularly well-suited for educational and research applications.
Academic institutions face mounting pressure to ensure information reliability and maintain research integrity. Self-RAG introduces a novel approach where AI systems develop the capability to critically evaluate their own outputs, making it particularly well-suited for educational and research applications.
What is Self-RAG
Self-Reflective Retrieval-Augmented Generation (Self-RAG) enhances LLM quality and factuality through a combination of retrieval and self-reflection capabilities. This framework trains models to adaptively retrieve passages on-demand and generate special tokens called "reflection tokens" that critique the model's own outputs.
The architecture represents a fundamental shift from passive information delivery to active self-assessment. Models trained with Self-RAG develop the ability to question their own knowledge base, verify claims against retrieved sources, and acknowledge limitations in their understanding—capabilities that prove essential in academic environments where source verification and factual accuracy determine the value of research outputs.
Education and Research Use Cases
Academic applications benefit significantly from Self-RAG's verification capabilities:
- Research synthesis: The system connects findings from multiple studies while maintaining rigorous citation standards and factual verification
- Literature review assistance: Self-RAG automatically evaluates source credibility and cross-references claims against established research databases
- Personalized learning: Students receive information tailored to their knowledge level, with built-in fact-checking to prevent the spread of misinformation
The architecture proves particularly valuable in research environments where the cost of inaccurate information extends beyond immediate consequences to long-term academic reputation and research validity.
Self-RAG Pros and Cons
Pros:
- Enhanced factual accuracy through self-verification mechanisms
- Improved relevance and support for generated content
- Superior performance in knowledge-intensive academic tasks
- Better citation and verifiability of sources
Cons:
- Increased computational complexity from multiple evaluation steps
- Implementation challenges requiring sophisticated training protocols
- Potential for overcaution that might limit creative responses
- Higher resource requirements compared to simpler architectures
Academic institutions implementing Self-RAG must balance these computational demands against the critical need for reliable, verifiable information in educational settings.
8. Agentic RAG (for Finance)
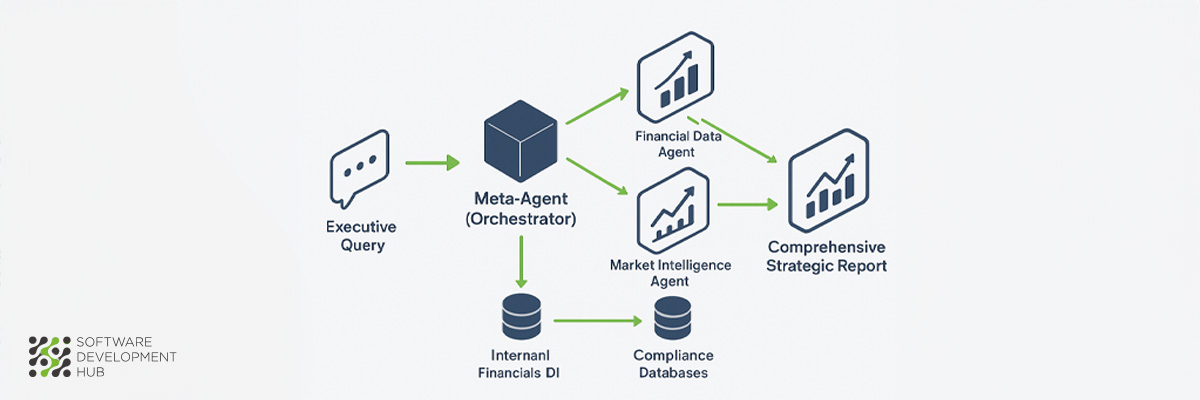 Financial institutions operate in environments where split-second decisions can impact millions of dollars in transactions. Agentic RAG architecture addresses this reality by incorporating autonomous AI agents that can independently plan, execute, and refine retrieval strategies—capabilities essential for modern financial operations.
Financial institutions operate in environments where split-second decisions can impact millions of dollars in transactions. Agentic RAG architecture addresses this reality by incorporating autonomous AI agents that can independently plan, execute, and refine retrieval strategies—capabilities essential for modern financial operations.
What is Agentic RAG
Agentic RAG introduces autonomous decision-making agents directly into the retrieval pipeline, creating a system that operates more like skilled financial analysts than traditional search mechanisms. These agents possess planning capabilities, tool utilization skills, and collaborative abilities that enable them to dynamically manage retrieval strategies and iteratively refine their understanding of complex financial contexts.
The architecture moves beyond static retrieval patterns by implementing intelligent agents that evaluate information independently, orchestrate sophisticated workflows, and adapt their approach based on changing market conditions or regulatory requirements. This autonomous decision-making capability optimizes the entire RAG process, making it particularly valuable for financial applications where both precision and adaptability determine success.
Finance Use Cases
Financial services organizations have documented significant improvements across multiple applications:
- Risk Assessment: Agents simultaneously evaluate multiple risk factors, providing comprehensive views of potential investment threats and market vulnerabilities
- Fraud Detection: The architecture demonstrates exceptional capability in identifying subtle patterns indicative of fraudulent activity, with documented implementations showing error rate reductions of approximately 78% compared to traditional RAG baselines
- Cash Application: AI agents analyze historical payment patterns to predict missing remittances, automatically generating correspondence to request necessary information
- Credit Management: The system creates dynamic customer credit profiles by accessing real-time financial data and trade behaviors, continuously updating risk assessments
Agentic RAG Pros and Cons
Advantages:
- Autonomous Decision-Making: Agents independently evaluate and manage retrieval strategies based on query complexity analysis
- Enhanced Accuracy: Documented error rate reductions of approximately 78% compared to traditional RAG implementations
- Adaptive Workflows: Dynamic task orchestration enables efficiency in real-time financial applications
- Improved Contextual Understanding: Iterative refinement through feedback loops enhances response quality
Limitations:
- Implementation Complexity: Requires careful orchestration of multiple components and introduces additional system dependencies
- Increased Latency: Multi-agent processing can add response time if not properly optimized
- Higher Operational Costs: Multiple agents and iterative processing increase computational expenses
- Reliability Considerations: Agents may struggle with highly complex tasks and occasionally fail to complete assigned operations
For financial institutions balancing accuracy requirements, adaptability needs, and computational efficiency, Agentic RAG provides a sophisticated solution that mimics human analytical processes while scaling to meet enterprise-level demands.
Implementation Strategy and Future Outlook
The analysis of these eight RAG architectures reveals distinct patterns in their development and application. Organizations can now select architectures based on specific operational requirements rather than adopting one-size-fits-all solutions. The progression from Simple RAG to Agentic RAG demonstrates increasing sophistication in handling domain-specific challenges while managing computational resources effectively.
What determines the optimal architecture choice for your organization? The decision depends on three primary factors: query complexity, accuracy requirements, and available computational resources. Small businesses may find Simple RAG sufficient for basic customer interactions, while regulated industries like healthcare and finance require architectures with built-in verification mechanisms.
The development trajectory suggests that hybrid implementations will become more prevalent. We expect to see organizations combining elements from different architectures—perhaps using Adaptive RAG's resource optimization with Self-RAG's verification capabilities for applications requiring both efficiency and accuracy. This modular approach allows teams to optimize performance characteristics for specific use cases without over-engineering simpler requirements.
RAG implementation success depends heavily on data quality and architecture alignment with business objectives. Companies achieving the best results focus on curating high-quality knowledge bases and selecting architectures that match their accuracy and latency requirements. The comparison table demonstrates that no single architecture excels across all dimensions—each represents deliberate trade-offs between capability and complexity.
Looking ahead, we anticipate continued refinement in autonomous decision-making capabilities, particularly in financial and healthcare applications where precision directly impacts outcomes. The integration of feedback mechanisms and self-correction features will likely become standard components across all architecture types, making reliable AI systems more accessible to organizations with varying technical capabilities.
Your RAG architecture selection should align with both current operational needs and future scaling requirements. Start with architectures that match your immediate complexity requirements, then plan migration paths as your data quality and technical capabilities mature.
Categories
About the author

CEO & Co-Founder at Software Development Hub. Innovation-driven expert with 20+ years of experience. A business practitioner with experience in creating and launching startups, an innovator and progressive-minded specialist, who helps turn raw ideas into profitable results.
Share



Need a project estimate?
Drop us a line, and we provide you with a qualified consultation.