The Solution: RAG Architecture
Traditional AI vs RAG Architecture
Traditional AI Systems
RAG Architecture
Why Enterprises Are Adopting RAG Architecture
How RAG AI Architecture Works: Step-by-Step
Step 1 — Data Ingestion
Step 2 — Document Processing and Chunking
Step 3 — Embeddings and Vector Storage
Step 4 — Query Processing and Retrieval
Step 5 — Response Generation Using LLMs
None
Data Sources Layer
Retrieval Layer
Generation Layer
Orchestration Layer
Monitoring and Feedback Layer
Benefits of RAG AI Architecture for Businesses
Common Use Cases of RAG Architecture in Enterprises
Challenges in Building RAG AI Architecture
How SDH Builds Enterprise-Ready RAG Architecture
Future Trends in RAG AI Architecture
To conclude
RAG AI Architecture Explained: A Practical Guide for Business Leaders

AI is rapidly moving from a "nice-to-have" to a core business engine, powering everything from customer support to internal research. But as early adopters found out, standard AI models have a major flaw: they can be confidently wrong.
Because traditional Large Language Models (LLMs) rely solely on their pre-trained data, they often struggle with outdated info or "hallucinations." In high-stakes fields like finance, law, or healthcare, that's a risk most companies can’t afford to take.
The Solution: RAG Architecture
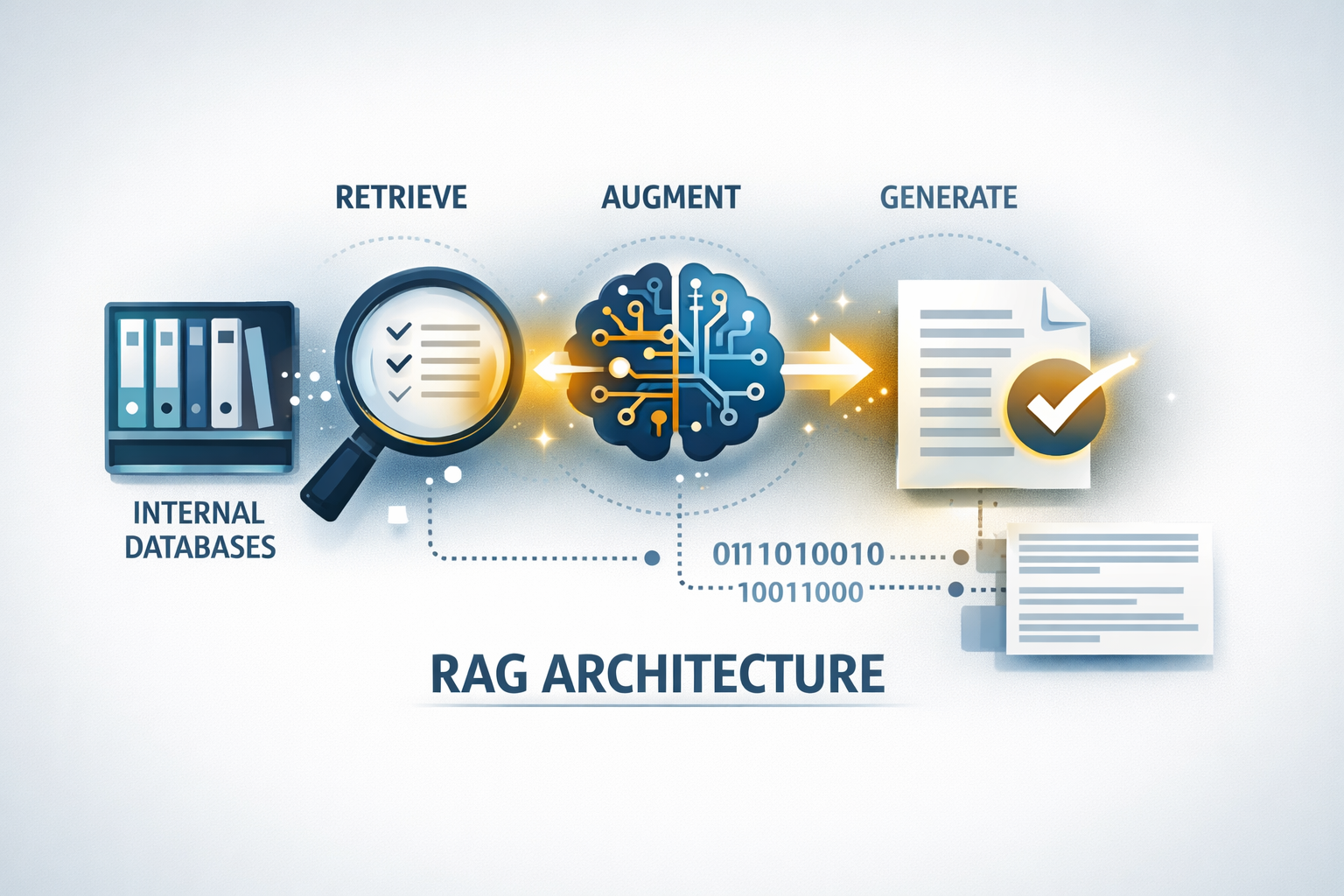
Retrieval-Augmented Generation (RAG) solves this by giving the AI a "living" library. Instead of relying on its memory, a RAG system:
- Retrieves specific, up-to-date facts from your company’s internal databases or documents.
- Augments those facts with the reasoning power of the AI.
- Generates a response that is grounded in real, verifiable data.
For business leaders, RAG means moving past the hype and into reliable, context-aware AI. Whether you’re just starting to explore or are ready for a full-scale rollout, understanding this architecture is the key to building an AI strategy that actually works for the enterprise.
Traditional AI vs RAG Architecture
To understand the importance of RAG, it helps to compare it with traditional AI models.
Traditional AI Systems
Traditional language models are trained using large datasets collected at a specific point in time. After training, their knowledge becomes fixed unless the model is retrained.
This creates several limitations:
- Outdated knowledge
- Limited access to proprietary company data
- Risk of hallucinations (incorrect answers)
- High retraining costs
For example, if a company updates its internal policies, a traditional AI model may not recognize those changes unless it is retrained — which can be time-consuming and expensive.
RAG Architecture
RAG systems solve this problem by retrieving information dynamically from trusted sources.
Instead of guessing answers, the system:
- Searches relevant data
- Retrieves the most useful information
- Generates a response based on real data
This makes RAG architecture especially valuable for businesses managing large volumes of internal knowledge.
Why Enterprises Are Adopting RAG Architecture
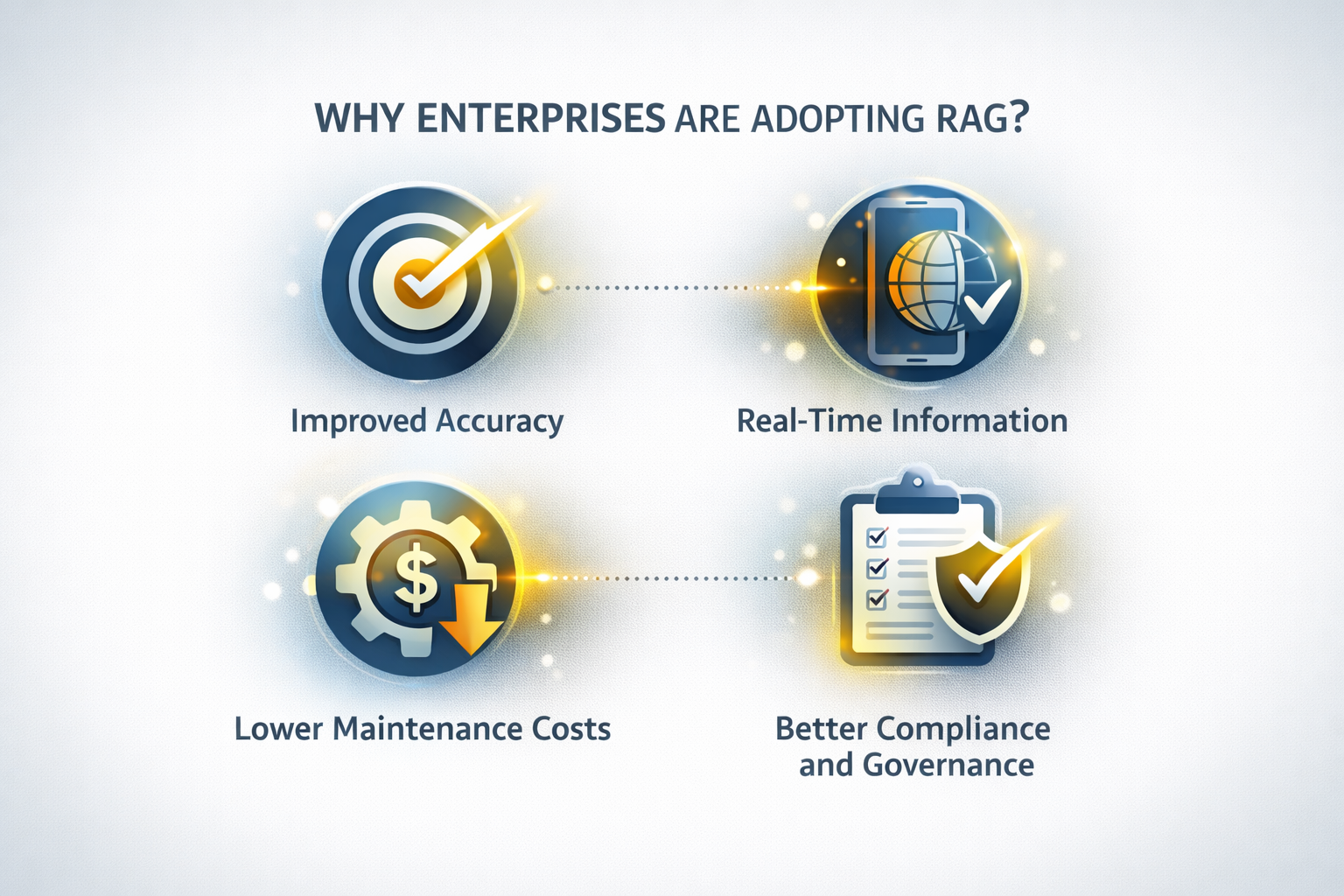
Businesses across industries are increasingly adopting RAG systems because they address some of the biggest limitations of traditional AI.
Key reasons include:
Improved Accuracy
RAG reduces hallucinations by grounding responses in real data sources. This improves trust in AI-generated answers.
Real-Time Information Access
Companies can connect RAG systems to:
- Internal databases
- Knowledge bases
- Policy documents
- Customer records
This ensures responses always reflect the latest information.
Lower Maintenance Costs
Unlike full model retraining, RAG systems only require updating the data source — not the entire model.
Better Compliance and Governance
Organizations can control exactly which data sources are used, making it easier to meet security and compliance requirements.
How RAG AI Architecture Works: Step-by-Step
RAG architecture follows a structured workflow that combines data retrieval with AI generation to deliver accurate, context-aware responses.
Step 1 — Data Ingestion
The process begins by collecting data from sources such as documents, databases, websites, CRMs, APIs, and internal knowledge systems. During ingestion, data is cleaned, standardized, and deduplicated to ensure reliable outputs.
Step 2 — Document Processing and Chunking
Documents are divided into smaller sections called chunks, making them easier to search and process. Metadata such as titles, categories, and dates may also be added to improve retrieval accuracy.
Step 3 — Embeddings and Vector Storage
Chunks are converted into embeddings — numerical representations of text that capture meaning. These embeddings are stored in a vector database, enabling fast semantic searches based on meaning rather than exact keywords.
Step 4 — Query Processing and Retrieval
When a user submits a question, it is converted into an embedding. The system searches the vector database to retrieve the most relevant content using semantic or hybrid search methods.
Step 5 — Response Generation Using LLMs
The retrieved content is sent to a language model, which generates a response based on both the user’s question and relevant data. This augmented generation improves accuracy, relevance, and context understanding, delivering reliable responses within seconds.
Core Components of Enterprise RAG Architecture
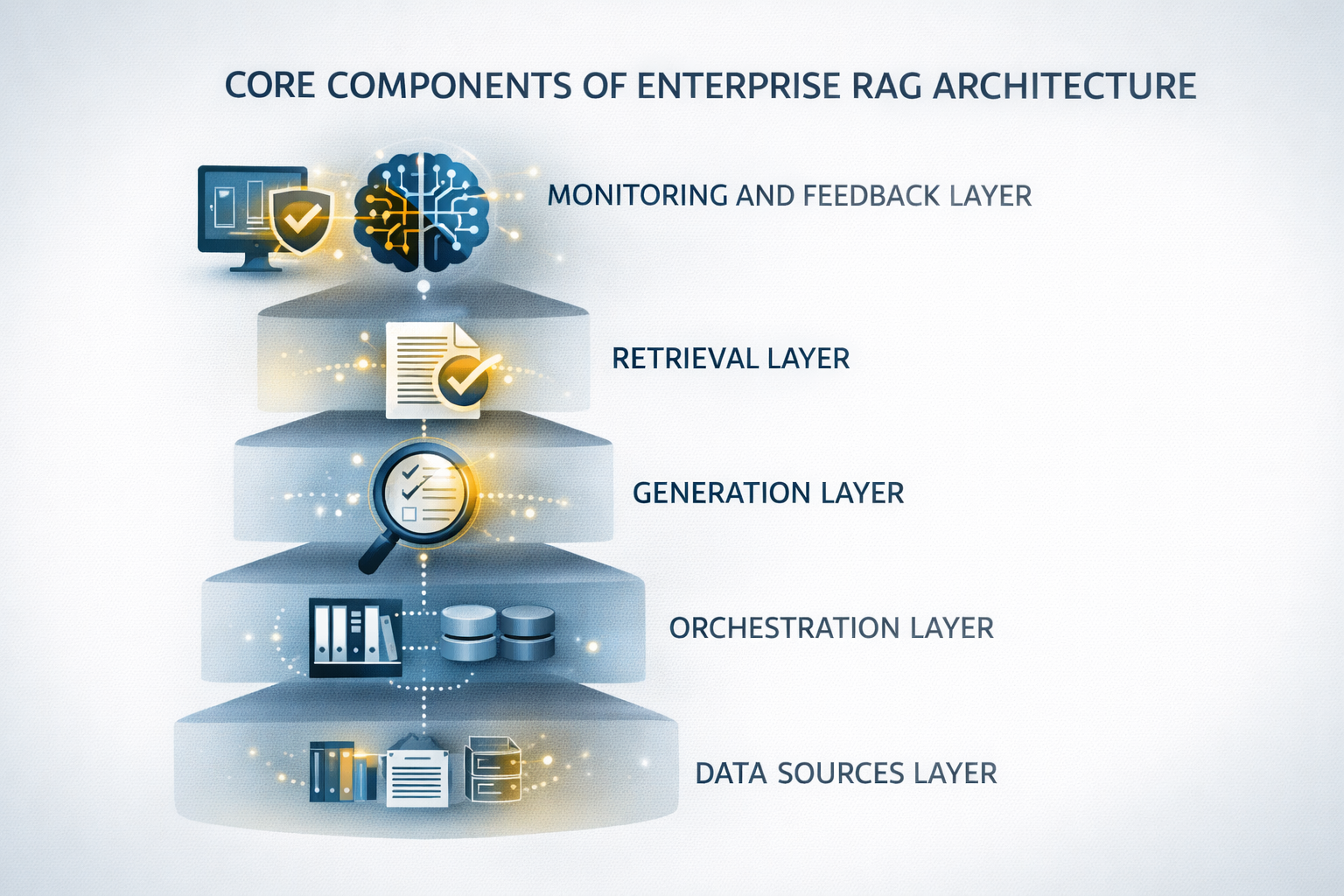
A successful RAG system is not just a single tool but a structured architecture made up of interconnected components. Each layer plays a specific role in making the system reliable, scalable, and suitable for enterprise use. Understanding these components helps business leaders evaluate AI solutions and make informed technical decisions.
Data Sources Layer
Every RAG system begins with data. This layer defines where the system retrieves its information from and brings multiple knowledge sources into one unified environment.
Common enterprise data sources include:
- Internal documents (PDFs, Word files, spreadsheets)
- Knowledge bases
- CRM and ERP systems
- Product documentation
- Email archives
- Databases and APIs
- Cloud storage systems
For example, a financial services company might connect compliance documents, client policies, investment reports, and market research files. This allows employees to ask natural-language questions and receive accurate answers from trusted sources.
The quality of these data sources directly affects system performance. Well-structured and organized data leads to more reliable AI responses.
Retrieval Layer
The retrieval layer locates the most relevant information from available data sources. This is one of the most critical parts of the system.
Instead of manual searches, this layer uses techniques such as:
- Semantic search
- Vector similarity search
- Hybrid search (keywords + meaning)
- Ranking algorithms
These methods allow the system to find relevant information even when exact words are not used. For instance, a question about remote work policies can still retrieve a document titled "Flexible Workplace Guidelines."
This capability significantly improves productivity, especially in large organizations with extensive documentation.
Generation Layer
After relevant content is retrieved, the generation layer produces the final response using a large language model (LLM).
The model:
- Understands the user's question
- Analyzes retrieved content
- Generates a structured answer
Rather than inventing responses, the model relies on retrieved information as its primary source. This approach reduces hallucinations, improves accuracy, and builds trust in AI-generated outputs.
Reliable responses are essential for business environments where accuracy directly impacts decision-making.
Orchestration Layer
The orchestration layer manages the workflow of the entire RAG system. It coordinates all components so they function smoothly together.
Typical orchestration tasks include:
- Managing search workflows
- Selecting retrieval strategies
- Formatting prompts
- Routing requests
- Handling system logic and errors
Without orchestration, system components would operate independently, leading to inconsistent performance. Modern enterprise RAG systems depend on orchestration frameworks to ensure stability and scalability.
Monitoring and Feedback Layer
A production-ready RAG system requires continuous monitoring. This layer tracks system performance and helps teams improve results over time.
Key metrics include:
- Response accuracy
- Query latency
- Retrieval quality
- System uptime
- User feedback
Organizations often implement feedback loops that allow users to rate responses, flag errors, and suggest improvements. This feedback helps refine the system and maintain high-quality performance.
Over time, monitoring becomes one of the most valuable tools for sustaining reliable and efficient AI operations.
Benefits of RAG AI Architecture for Businesses

RAG architecture offers measurable advantages across departments and industries. These benefits go far beyond simple automation — they influence productivity, decision-making, and operational efficiency.
- Improved Accuracy and Reliability
- Real-Time Knowledge Access
- Enhanced Decision-Making
- Cost Efficiency Compared to Model Training
Common Use Cases of RAG Architecture in Enterprises
RAG architecture is highly flexible and supports a wide range of business applications. Organizations across industries are already using RAG systems to improve workflows and enhance customer experiences.
Enterprise Knowledge Management
Large organizations often struggle with fragmented information.
Employees spend valuable time searching for answers across multiple systems.
RAG-powered knowledge platforms centralize information and allow employees to ask natural-language questions.
Example queries:
- "What is the onboarding process for new hires?"
- "How do we handle product returns?"
- "Where can I find the cybersecurity guidelines?"
Instead of searching manually, employees receive instant responses.
This improves productivity and reduces training time for new staff.
Challenges in Building RAG AI Architecture
While RAG architecture offers powerful capabilities, building a production-ready system is not without challenges. Organizations that understand these risks early are better prepared to implement reliable and scalable solutions.
Most implementation challenges fall into four key areas:
- Data Quality and Preparation
- Latency and Performance Issues
- Security and Compliance Requirements
- Integration with Existing Systems
Successful integration requires careful planning and strong technical expertise.
Organizations that invest in flexible integration strategies experience smoother implementation processes and fewer disruptions.
How SDH Builds Enterprise-Ready RAG Architecture
Building a reliable RAG system requires structured methodology, strong engineering, and continuous optimization. Organizations that partner with experienced teams gain access to proven frameworks and scalable solutions.
Custom Architecture Design
Every organization has unique needs. The process begins with understanding workflows, identifying data sources, and defining performance goals to ensure the system aligns with real business operations.
Enterprise-Grade Security
Security is built into every layer through access controls, secure data pipelines, encryption, and compliance-ready workflows that protect sensitive information.
Performance Optimization
Continuous tuning improves retrieval speed, query efficiency, and infrastructure scalability to maintain reliable performance under growing workloads.
Continuous Support and Improvement
Ongoing monitoring, data updates, accuracy improvements, and feature expansion ensure the system continues to deliver long-term value.
Future Trends in RAG AI Architecture
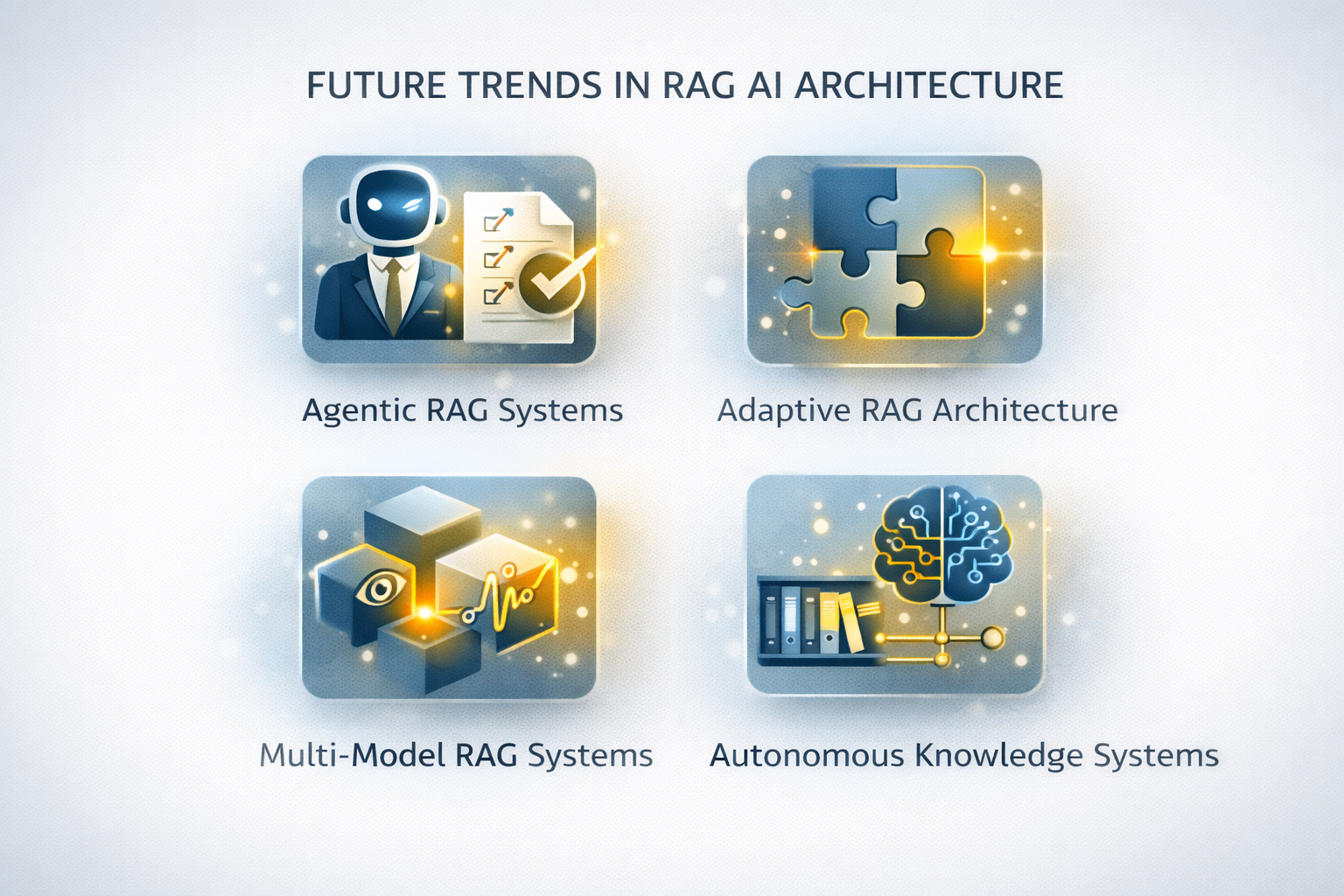
RAG technology continues to evolve rapidly. Several emerging trends are shaping the future of enterprise AI architecture.
Organizations that stay informed about these trends are better positioned to adopt innovative solutions.
- Agentic RAG Systems
- Adaptive RAG Architecture
- Multi-Model RAG Systems
- Autonomous Knowledge Systems
To conclude
RAG AI architecture is transforming enterprise AI by combining real-time data retrieval with language generation to deliver more accurate and reliable responses.
Organizations that adopt well-designed RAG systems improve productivity, knowledge management, and decision-making. However, long-term success depends on strong data quality, security, performance, and scalability. Companies that invest in custom RAG architecture are better positioned to stay competitive as AI continues to evolve.
Categories
About the author

Business Analyst at Software Development Hub with extensive experience in business process analysis and B2C&B2B software development. Possesses strong social skills, a creative and strategic mindset, and leadership abilities that contribute to successful team management and project execution.
Share



Need a project estimate?
Drop us a line, and we provide you with a qualified consultation.