What Is a RAG Pipeline?
How a RAG Pipeline Works
Why RAG Pipelines Are Valuable
What Are Traditional LLM Approaches?
Why Traditional LLMs Are Useful
Where They Struggle
RAG Pipeline vs. Traditional LLM: Key Differences
Use Cases for Both Approaches
Best Use Cases for Traditional LLM Approaches
Challenges to Consider
Current Trends in AI That Influence This Choice
How to Choose the Right Approach for Your Project
How SDH Can Help You
RAG Pipeline vs. Traditional LLM Approaches: Which Is Right for Your Project?
Artificial intelligence is advancing at a remarkable pace, and organizations today face an important architectural choice when building intelligent applications: Should you rely on a RAG Pipeline or a Traditional LLM approach?
While both approaches use large language models (LLMs), they work very differently and serve different types of use cases. Making the right decision has a direct impact on accuracy, user trust, cost, scalability, and long-term product strategy.
We shall break down the differences in simple terms, highlight strengths and limitations, and provide real-world examples to help you choose the best fit for your next AI project.
What Is a RAG Pipeline?
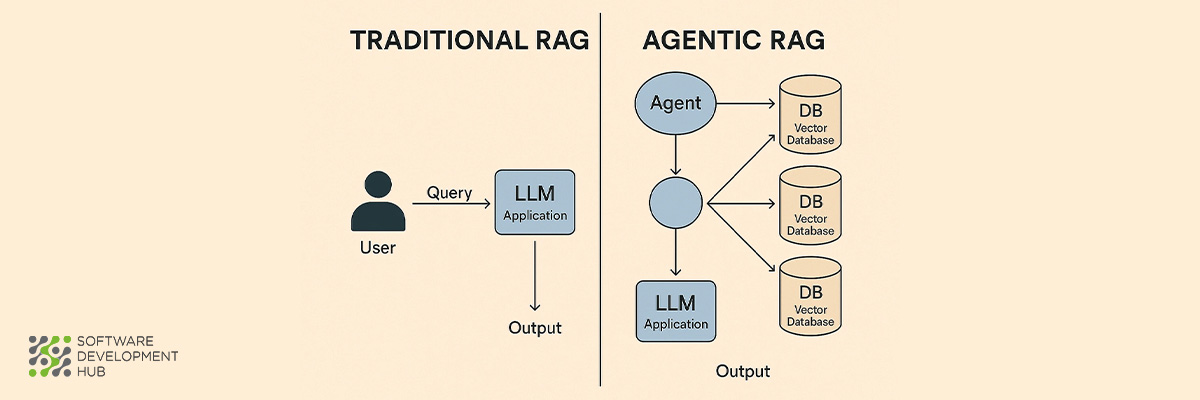 A RAG Pipeline (Retrieval-Augmented Generation) enhances a language model by connecting it to an external knowledge source — such as documentation, PDFs, databases, or websites. When a user asks a question, the system retrieves relevant information and passes it to the LLM to generate a grounded answer.
A RAG Pipeline (Retrieval-Augmented Generation) enhances a language model by connecting it to an external knowledge source — such as documentation, PDFs, databases, or websites. When a user asks a question, the system retrieves relevant information and passes it to the LLM to generate a grounded answer.
How a RAG Pipeline Works
- User query
- Retriever searches for relevant documents in a vector database
- LLM (Reader) uses the retrieved content to answer
- Post-processing adds citations, summaries, or formatting
Why RAG Pipelines Are Valuable
- More accurate answers — grounded in real data
- Up-to-date knowledge — just update documents, not the model
- User trust — you can show citations and sources
- Scalability — perfect for large or fast-changing knowledge bases
Example
A support chatbot retrieves actual product documentation when answering a customer’s question. It doesn’t “guess”; it references the source.
What Are Traditional LLM Approaches?
 A Traditional LLM relies entirely on what the model already knows. It may use:
A Traditional LLM relies entirely on what the model already knows. It may use:
- Prompt engineering
- Fine-tuning
- Instruction tuning
- Large-context prompting
No retrieval step is involved.
Why Traditional LLMs Are Useful
- Simpler architecture — fewer moving parts
- Lower latency — fast responses
- Great for creative tasks — ideation, brainstorming, content generation
- Ideal for quick prototypes
Where They Struggle
- Knowledge becomes stale over time
- Higher risk of hallucinations
- Expensive to fine-tune for large, domain-specific knowledge
Example
A digital assistant generates branding ideas for a designer — no factual accuracy required.
RAG Pipeline vs. Traditional LLM: Key Differences
|
Dimension |
RAG Pipeline |
Traditional LLM |
|
Accuracy |
High, because answers are grounded |
Moderate; hallucination risk |
|
Knowledge freshness |
Easy to update |
Requires re-training or new model |
|
Infrastructure |
Vector DB + retriever + LLM |
LLM only |
|
Latency |
Slightly higher |
Lower |
|
Transparency |
Can show citations |
Harder to justify answers |
|
Cost |
Higher operations cost |
Higher fine-tuning cost |
|
Ideal for |
Knowledge-heavy applications |
Creative or conversational apps |
Use Cases for Both Approaches
Best Use Cases for a RAG Pipeline
-
Customer support assistants
- Legal or compliance tools
- Research assistants
- Financial analysis tools
- Documentation search portals
- Medical, scientific, or technical question-answering
- Enterprise knowledge bases
If accuracy and trust matter, RAG is the right choice.
Best Use Cases for Traditional LLM Approaches
- Creative writing and ideation
- Marketing content generation
- Educational tutors
- Brainstorming assistants
- Code generation with light context
- Low-latency chatbots
- Personal productivity tools
If creativity and speed matter more than strict factual accuracy, Traditional LLMs shine.
Challenges to Consider
Challenges of RAG Pipelines
- Requires more infrastructure (vector DB, embeddings, orchestration)
- Retrieval must be tuned properly (chunk sizes, ranking)
- Latency can increase if not optimized
- Sensitive data requires secure indexing and access control
Challenges of Traditional LLMs
- Hard to keep knowledge up to date
- Hallucination risk is higher
- May require costly fine-tuning for large domains
- Cannot easily justify answers without citations
Current Trends in AI That Influence This Choice
The landscape is shifting quickly, and several trends make RAG more accessible — and Traditional LLMs more powerful.
Trends Boosting RAG Pipeline Adoption
- Multimodal retrieval (images, videos, tables)
- Cheaper vector databases and managed retrieval services
- Improved rerankers for higher accuracy
- Enterprise demand for explainability and compliance
Trends Strengthening Traditional LLMs
- Massive context windows (hundreds of thousands of tokens)
- Stronger instruction-following skills
- Lightweight, cheap fine-tuning methods (LoRA, QLoRA)
- Local/on-device models for privacy-sensitive applications
How to Choose the Right Approach for Your Project
 Ask yourself these questions:
Ask yourself these questions:
1. Do you need factual accuracy and citations?
→ Choose a RAG Pipeline
2. Is low latency essential?
→ Traditional LLM
3. Is your knowledge base large or rapidly changing?
→ RAG Pipeline
4. Are you building a prototype quickly?
→ Traditional LLM
5. Do you need user trust or regulatory compliance?
→ RAG Pipeline
How SDH Can Help You
Both RAG Pipelines and Traditional LLM approaches are powerful — but they’re built for different goals.
- If your application depends on factual accuracy, fresh knowledge, explainability, and user trust, a RAG Pipeline is the clear winner.
- If your goal is creativity, speed, or rapid prototyping**, then the Traditional LLM approach is more efficient.
The strongest AI products often combine both approaches depending on the feature or workflow.
At SDH Global, we specialize in designing, building, and deploying AI systems that are production-ready, scalable, secure, and cost-optimized — whether you need a RAG Pipeline, a Traditional LLM, or a hybrid architecture.
If you’re exploring whether a RAG Pipeline or Traditional LLM is right for your next project, SDH can guide you from strategy to production.
SDH can help you choose the right approach, design the right experience, and build a solution that grows with your users and your business.
Categories
About the author

Business Analyst at Software Development Hub with extensive experience in business process analysis and B2C&B2B software development. Possesses strong social skills, a creative and strategic mindset, and leadership abilities that contribute to successful team management and project execution.
Share



Need a project estimate?
Drop us a line, and we provide you with a qualified consultation.