Natural Language Processing Applications

The Natural Language is a principal method of human communication. It comprises of words and is expressed by means of text, speech and gestures. The gesture is not the main character of this post so were going to proceed with text and speech. In our digitalized world we are highly encouraged to communicate with devices and by the way reading this post is indeed a communication by text. All these factors have led to a fact that NLP has become in the front lines of ML / DS topics. So what do we know about NLP ?
What is NLP?
Natural Language Processing (NLP) is a subfield of AI that deals with making computers to understand text and spoken words just like we humans do. This field is highly valuable for businesses to process and get insights from huge volume of data coming from emails, social media, chats, surveys etc. NLP is a technology that is already in use my many businesses and we are going to cover some of them in the below sections.
NLP today goes beyond text and speech — it integrates multimodal inputs (image, video, audio + text). Models are also multilingual by default, supporting low-resource languages with higher accuracy. Retrieval-Augmented Generation (RAG) has become a standard to reduce hallucinations, grounding outputs in reliable sources.
Sentiment Analysis

The way we talk is often accompanied with the phrases, sentiments or sarcasm that overcomplicate the literal meaning of words. These factors are frequently faced in Social Media and are quite difficult for computers to understand. This is where NLP mainly its subset NLU (Natural Language Understanding) comes in place. With NLU computers can differentiate among the sentiments and identify a tone of text. Sentiment analysis is a NLP method for identifying the positivity, negativity, or neutrality of data. Businesses frequently do sentiment analysis on textual data to track the perception of their brands and products in customer reviews and to better understand their target market.
There are several ways NLP can be used for Sentiment Analysis task. These are:
- Rule-based — uses some NLP techniques such as stemming, tokenizations, part-of-speech tagging. Works as follows: define the words for each group(negative/ positive), count the number of each word groups occurring in a sentence. Depending on the count number of each sentiment group finds if sentence is positive or negative. If even returns neutral. But the rule-based approach may reach up to a very complex system.
- Automatic — this is where ML is implemented. Sentiment Analysis is usually a classification problem. We have labelled data and trying to find a proper sentiments given the data of sentences with reviews/ comments/ feedbacks etc. The key aspect of this approach is a proper. feature extraction and preparing the feature vectors. For this we use Bag-of-words, Word Embeddings, TF-IDF.
- Hybrid — combination of the above mentioned techniques. Usually results in more accurate results.
By 2025, sentiment analysis detects nuanced emotions (sarcasm, frustration, humor) and tone shifts, not just polarity. Real-time monitoring tools now integrate directly with customer service systems to adapt responses instantly. Hybrid ML + LLM approaches outperform older bag-of-words or rule-based methods.
Stay tuned for Airline Sentiment Analysis implementation.
Language Translation
Everyone has ever been in need to translate something very quickly. Be it Google Translate or any other similar application. Such applications are based on a technique called Machine Translation. It is defined as a process of automatically converting text form one language to another without losing the meaning. Comparing to the times when translator applications were built on top of the dictionaries which is a rule-based approach to a problem, the current state-of-the-art machine translation approach (NMT) uses the neural network to predict the likelihood of words. The biggest advantage of NMT compared to SMT (Statistical Machine Translation) and Rule-based, is high speed and capability to learn words and reuse then upon requirement.
Neural Machine Translation (NMT) is now real-time and multimodal — speech-to-speech systems (like Google’s Gemini or Meta’s SeamlessM4T) allow fluid conversation across languages. Regional dialect support and code-switching handling are major advances since 2023.
Auto Correction and Prediction
Today, there are several programs available that may help us avoid spelling and grammar errors in our emails, messages, and other documents by checking the grammar and spelling of the text we enter (Ex. Grammarly). NLP is crucial technology in this applications. These programs include a wide range of functions, including the ability to suggest synonyms, fix grammatical and spelling errors, rephrase words for clarity, and even estimate the implicit tone of a statement from the user. Another NLP function called “auto prediction” proposes automated text prediction for the text we have already started to type. This helps the user save time and makes their job simpler. These are the steps to building such models:
- Identify misspelled word.
- Search for strings that are N-edit-distance from the incorrect word.
- Filterring.
- Order based on word probabilities.
- Choose the best case.
Text Prediction is using n-grams based on the likelihood that it’s occurence. Continuous groups of words , tokes, or other symbols that appear in a document are called N-grams.
Beyond spelling and grammar, autocorrect systems now, in 2025, personalize corrections and predictions based on user style, domain, and context. On-device NLP allows offline predictions, improving privacy. AI writing assistants combine correction with stylistic tone guidance.
Targeted Advertising

You would frequently encounter advertisements for such things and other relevant products on other websites if you ever searched for any product or object in any online store. Online targeted advertising of this kind is referred to as targeted advertising and is carried out with the aid of NLP.
The essential component of targeted advertising is keyword matching. Only those who search for a term that is similar to the one with which the advertising was attached will see the Ads, which are linked to a certain word or phrase. That’s obviously insufficient; other factors, such as the subsequent websites they visited and the webpages they looked interested in, are also taken into account to give them the substantial advertisements of products they may be interested in.
Due to the fact that the advertising are only displayed to clients who are truly interested in the product, which is assessed based on their online behavior, many businesses have benefited greatly from this and have saved a significant amount of money.
In 2025, targeted advertising has shifted to context-aware personalization. NLP-driven ad systems now combine browsing behavior, real-time sentiment, and conversational cues to deliver more relevant ads. Privacy regulations (GDPR, DMA, US state laws) have forced companies to adopt federated and edge NLP approaches.
Chatbots

I personally think of Chatbots as an integral part of most businesses, government sites, providing online services nowadays. They are literally everywhere. So, what makes an AI powered bot different from Rule-based bot ?
We refer to the majority of common bots as “rule-based” bots. They are made to carefully adhere to the conversational guidelines that their author established. When a user enters a certain command, a rule-based bot will automatically provide a prewritten answer. A conventional bot, however, may struggle to give the user valuable information if those guidelines are not followed. The adaptability that is a crucial component of human dialogues is absent. These are the things that mainly make AI chatbot so special and valuable:
- Understanding Natural Language.
- The way of communication is no just a Q/A.
- Continuous improvement.
Read also: Data Lakes and Analytics on AWS
To train a chatbot to understand natural language, you will need a lot of data. Numerous sources, including social media, forums, and customer service records, can be used to get this information. To accommodate many circumstances, the data has to be diversified and labelled.
As a next step you must pre-process the data collected. Tokenizing the text into smaller bits, cleaning and normalizing the data are the crucial steps to perform.
- Text normalization — maintaining uniformity in the data, convert text to lowercase, remove punctuation, symbols, etc.
- Tokenization — breaking the text up into smaller pieces, such as words or phrases.
- Remove Stop Words — terms like “the,” “is,” and “and” from the text that don’t significantly add any meaning to the dataset.
- Lemmatization — reduces dimensionality of data.
- Part-of-speech Tagging — identify the grammatical role of each word in the text, such as a noun, verb, or adjective.
Then is it essential to understand which NLP technique suit your business requirements. It can be a Sentiment Analysis, Machine Learning based approach, Keyword matching system, or a Language Model.
Modern chatbots go far beyond FAQ bots. In 2025, they act as agentic assistance capable of reasoning, handling multi-turn conversations, and executing actions (booking, purchases, scheduling). Grounded in external databases and with long-term memory, they provide consistent, factual interactions across industries.
ChatGPT and NLP
This blogpost should not be ending without mentioning trending ChatGPT. A state-of-the-art natural language processing (NLP) model developed by OpenAI — ChatGPT is a variation of the well-known GPT-3 (Generative Pertained Transformer 3) model, which was trained on a huge amount of text data (~ 570GB of datasets, including web pages, books, and other sources) to produce human-like replies. It is an expansion of the Large Language Model (LLM) class of machine learning Natural Language Processing models. Huge amounts of textual information are ingested by LLMs, which then infer associations between words in the text. As computer power has improved over the past few years, these models have expanded. LLMs get more powerful as their input datasets and parameter space get bigger. Language models analyze the text in the data to calculate the likelihood of the subsequent word. Several probabilistic methods are used to train language models. The GPT-3 is a family of models rather than a single model. The amount of trainable parameters varies among members of the same family of models. Quite a powerful tool with sufficient amount of limitations for now. Looking forward to investigate and test GPT4…
ChatGPT (and similar LLMs) have become standard infrastructure in business. In 2025, models integrate retrieval, plugins, and APIs, enabling automation of workflows. Enterprises now deploy domain-specific fine-tunedversions (finance, healthcare, law) to ensure compliance, security, and better accuracy.
Sentiment Analysis — Sample Codes
Let’s try to perform a Sentiment Analysis on Airline dataset.

Above we can see the main imports Natural Language Toolkit — a collection of libraries for NLP and stopwords — collection of words that don’t provide any meaning to a sentence, thus should be removed from the dataset.


Airline sentiment dataset

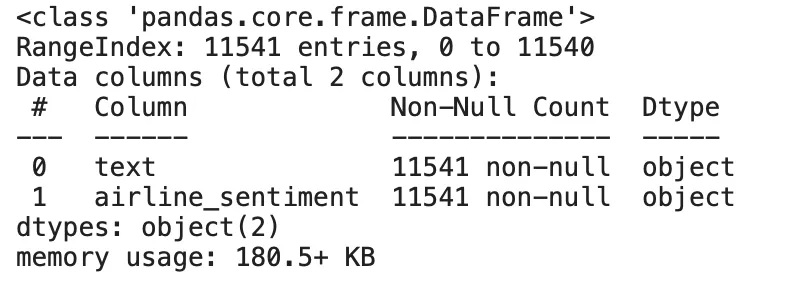
Checked that we don’t have any null values in our dataset.

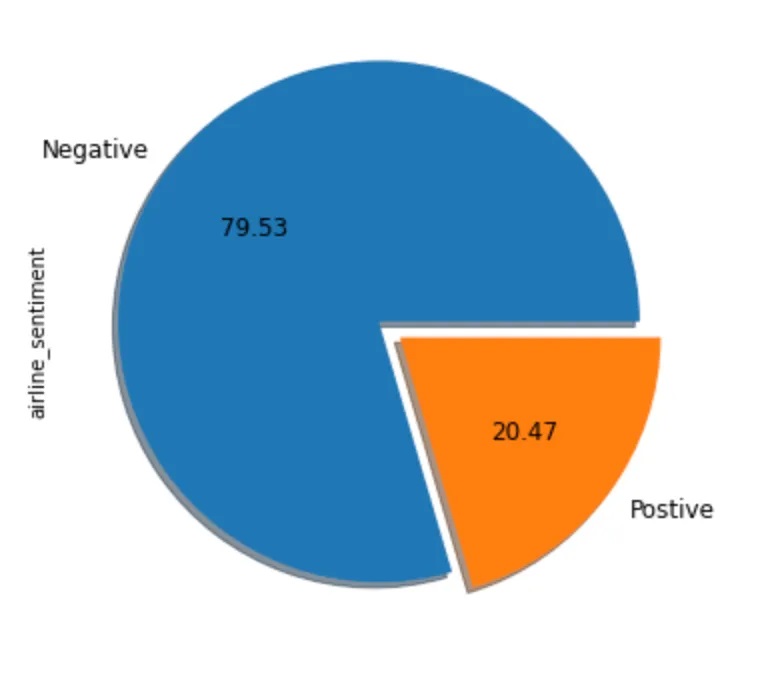
Distribution of tweets by sentiments in dataset
It is evident that we have imbalanced data towards the negative tweets. Therefore, we have to use the techniques to handle imbalanced data. SMOTE is one of the techniques that will generate a synthetic data to increase the number of positive cases in a balanced way.

Lemmatizing — eliminates all suffices and leaves only the root of the word.

The above code snippet is just a quick and simple cleaning of the text which removes the stop words, numbers and special characters from the text column.

The airline sentiment column was originally a String type column so we have to convert and make it numeric.

Converting label from String to int
Now we have to do the same for the cleaned text dataset. We are going to use TF-IDF vectorizer which converts the words into vectors by considering not only the number of times when a word appears but also the importance of that word.

Now getting back to imbalanced data problem as we left it pending.

Now that we are done with the dataset preparation we can reach our final steps of training the model and testing the results.

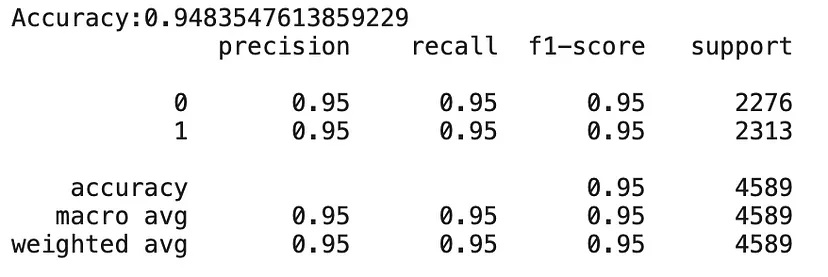
Monitoring the customer feedbacks and getting the sentiments from them helps the businesses to improve the quality of products and services. Thus, resulting in higher sales. There would be a much more value of this model is we could get data of a longer timeframe.
Software Development Hub is a team of like-minded people with extensive experience in software development, web and mobile engineering, custom enterprise software development. We create meaningful products, adhering to the business goals of the client. Main areas of development: digital health, accounting, education.
Categories
Share



Need a project estimate?
Drop us a line, and we provide you with a qualified consultation.