Was ist eine RAG-Pipeline?
Wie eine RAG-Pipeline funktioniert
Warum RAG-Pipelines wertvoll sind
Was sind traditionelle LLM-Ansätze?
Warum traditionelle LLMs nützlich sind
Wo ihre Grenzen liegen
RAG-Pipeline vs. traditioneller LLM: Zentrale Unterschiede
Anwendungsfälle für beide Ansätze
Beste Anwendungsfälle für eine RAG-Pipeline
Beste Anwendungsfälle für traditionelle LLM-Ansätze
Herausforderungen, die zu berücksichtigen sind
Herausforderungen von RAG-Pipelines
Herausforderungen traditioneller LLMs
Aktuelle KI-Trends, die diese Entscheidung beeinflussen
Trends, die die Einführung von RAG-Pipelines fördern
Trends, die traditionelle LLMs stärken
So wählen Sie den richtigen Ansatz für Ihr Projekt
Fazit: Welchen Ansatz sollten Sie wählen?
RAG-Pipeline vs. traditionelle LLM-Ansätze: Welche Lösung ist die richtige für Ihr Projekt?
Künstliche Intelligenz entwickelt sich in rasantem Tempo weiter, und Unternehmen stehen heute vor einer wichtigen architektonischen Entscheidung beim Aufbau intelligenter Anwendungen: Sollten Sie auf eine RAG-Pipeline oder auf einen traditionellen LLM-Ansatz setzen?
Beide Ansätze nutzen große Sprachmodelle (Large Language Models, LLMs), funktionieren jedoch sehr unterschiedlich und eignen sich für verschiedene Anwendungsfälle. Die richtige Wahl hat direkten Einfluss auf Genauigkeit, Nutzervertrauen, Kosten, Skalierbarkeit und die langfristige Produktstrategie.
Dieser Artikel erklärt die Unterschiede in einfachen Worten, beleuchtet Stärken und Einschränkungen und liefert praxisnahe Beispiele, die Ihnen helfen, die beste Lösung für Ihr nächstes KI-Projekt zu finden.
Was ist eine RAG-Pipeline?
Eine RAG-Pipeline (Retrieval-Augmented Generation) erweitert ein Sprachmodell, indem sie es mit einer externen Wissensquelle verbindet – zum Beispiel mit Dokumentationen, PDFs, Datenbanken oder Websites. Wenn ein Nutzer eine Frage stellt, ruft das System relevante Informationen ab und übergibt sie an das LLM, das daraus eine fundierte, faktenbasierte Antwort generiert.
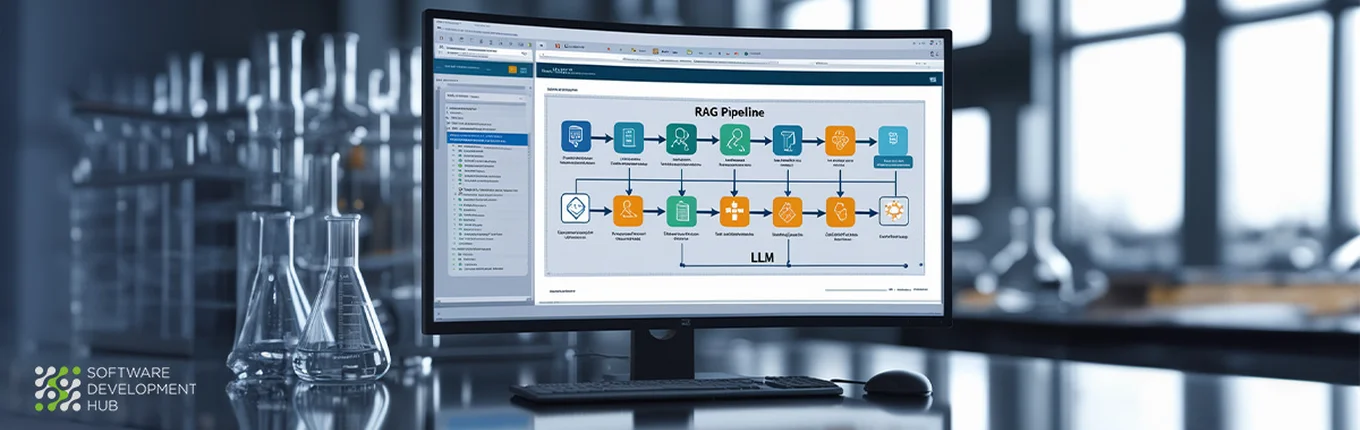
Wie eine RAG-Pipeline funktioniert
- Nutzer Anfrage
- Retriever sucht relevante Dokumente in einer Vektordatenbank
- LLM (Reader) nutzt die abgerufenen Inhalte zur Beantwortung der Anfrage
- Nachverarbeitung ergänzt Zitate, Zusammenfassungen oder Formatierungen
Warum RAG-Pipelines wertvoll sind
- Höhere Genauigkeit – Antworten sind in realen Daten verankert
- Aktuelles Wissen – Dokumente werden aktualisiert, nicht das Modell
- Nutzervertrauen – Quellen und Zitate können transparent angezeigt werden
- Skalierbarkeit – ideal für große oder sich schnell ändernde Wissensbestände
Beispiel
Ein Support-Chatbot greift bei der Beantwortung einer Kundenfrage auf echte Produktdokumentationen zu. Er „rät“ nicht, sondern verweist auf die zugrunde liegenden Quellen.
Was sind traditionelle LLM-Ansätze?
Ein traditioneller LLM-Ansatz verlässt sich vollständig auf das Wissen, das bereits im Modell enthalten ist. Dabei können unter anderem folgende Methoden zum Einsatz kommen:
- Prompt Engineering
- Fine-Tuning
- Instruction Tuning
- Large-Context Prompting
Ein separater Retrieval-Schritt ist nicht vorgesehen.
Warum traditionelle LLMs nützlich sind
- Einfachere Architektur – weniger Komponenten und Abhängigkeiten
- Geringere Latenz – schnelle Antwortzeiten
- Ideal für kreative Aufgaben – Ideenfindung, Brainstorming, Content-Erstellung
- Perfekt für schnelle Prototypen
Wo ihre Grenzen liegen
- Wissen veraltet mit der Zeit
- Höheres Risiko von Halluzinationen
- Teures Fine-Tuning bei umfangreichem, domänenspezifischen Wissen
Beispiel
Ein digitaler Assistent erstellt Branding-Ideen für einen Designer – faktische Genauigkeit ist dabei nicht entscheidend.
RAG-Pipeline vs. traditioneller LLM: Zentrale Unterschiede
|
Dimension |
RAG-Pipeline |
Traditioneller LLM |
|
Genauigkeit |
Hoch, da Antworten auf externen Quellen basieren |
Mittel; Risiko von Halluzinationen |
|
Aktualität des Wissens |
Einfach zu aktualisieren |
Erfordert erneutes Training oder ein neues Modell |
|
Infrastruktur |
Vektordatenbank + Retriever + LLM |
Nur LLM |
|
Latenz |
Etwas höher |
Niedriger |
|
Transparenz |
Quellen und Zitate können angezeigt werden |
Antworten sind schwerer nachzuvollziehen |
|
Kosten |
Höhere Betriebskosten |
Höhere Kosten für Fine-Tuning |
|
Ideal für |
Wissensintensive Anwendungen |
Kreative oder konversationelle Anwendungen |
Anwendungsfälle für beide Ansätze
Beste Anwendungsfälle für eine RAG-Pipeline
- Kundenservice-Assistenten
- Rechts- oder Compliance-Tools
- Forschungsassistenten
- Finanzanalyse-Tools
- Dokumentations-Suchportale
- Medizinische, wissenschaftliche oder technische Frage-Antwort-Systeme
- Unternehmens-Wissensdatenbanken
Wenn Genauigkeit und Vertrauenswürdigkeit entscheidend sind, ist RAG die richtige Wahl.
Beste Anwendungsfälle für traditionelle LLM-Ansätze
- Kreatives Schreiben und Ideengenerierung
- Marketing-Content-Erstellung
- Lern- und Nachhilfe-Assistenten
- Brainstorming-Assistenten
- Code-Generierung mit geringem Kontext Bedarf
- Chatbots mit niedriger Latenz
- Persönliche Produktivitäts-Tools
Wenn Kreativität und Geschwindigkeit wichtiger sind als strikte faktische Genauigkeit, überzeugen traditionelle LLMs.
Herausforderungen, die zu berücksichtigen sind
Herausforderungen von RAG-Pipelines
- Erfordert mehr Infrastruktur (Vektor-Datenbanken, Embeddings, Orchestrierung)
- Die Retrieval-Logik muss sorgfältig abgestimmt werden (Chunk-Größen, Ranking)
- Die Latenz kann steigen, wenn nicht ausreichend optimiert wird
- Sensible Daten erfordern sichere Indizierung sowie Zugriffs- und Berechtigungskontrollen
Herausforderungen traditioneller LLMs
- Wissen lässt sich nur schwer aktuell halten
- Höheres Risiko für Halluzinationen
- Für große Domänen kann kostspieliges Fine-Tuning erforderlich sein
- Antworten lassen sich nur schwer ohne Quellenangaben begründen
Aktuelle KI-Trends, die diese Entscheidung beeinflussen
Die Landschaft verändert sich rasant, und mehrere Trends machen RAG zugänglicher – während traditionelle LLMs gleichzeitig leistungsfähiger werden.
Trends, die die Einführung von RAG-Pipelines fördern
- Multimodales Retrieval (Bilder, Videos, Tabellen)
- Günstigere Vektor-Datenbanken und verwaltete Retrieval-Services
- Verbesserte Reranker für höhere Genauigkeit
- Steigende Nachfrage von Unternehmen nach Erklärbarkeit und Compliance
Trends, die traditionelle LLMs stärken
- Massive Kontextfenster (Hunderttausende von Tokens)
- Stärkere Fähigkeiten zur Befolgung von Anweisungen
- Leichte und kostengünstige Fine-Tuning-Methoden (LoRA, QLoRA)
- Lokale bzw. On-Device-Modelle für datenschutz sensible Anwendungen
So wählen Sie den richtigen Ansatz für Ihr Projekt
Stellen Sie sich folgende Fragen:
- Benötigen Sie faktische Genauigkeit und Quellenangaben?
→ RAG-Pipeline wählen - Ist eine niedrige Latenz entscheidend?
→ Traditionelles LLM - Ist Ihre Wissensbasis groß oder ändert sie sich schnell?
→ RAG-Pipeline - Möchten Sie schnell einen Prototyp entwickeln?
→ Traditionelles LLM - Benötigen Sie Nutzervertrauen oder regulatorische Compliance?
→ RAG-Pipeline
Fazit: Welchen Ansatz sollten Sie wählen?
Sowohl RAG-Pipelines als auch traditionelle LLM-Ansätze sind leistungsstark – jedoch für unterschiedliche Ziele konzipiert.
Wenn Ihre Anwendung auf faktischer Genauigkeit, aktuellem Wissen, Erklärbarkeit und Nutzervertrauen basiert, ist eine RAG-Pipeline die klare Wahl.
Wenn Ihr Ziel hingegen Kreativität, Geschwindigkeit oder schnelles Prototyping ist, ist der traditionelle LLM-Ansatz effizienter.
Die stärksten KI-Produkte kombinieren oft beide Ansätze, abhängig von Funktion oder Workflow.
Bei SDH Global sind wir darauf spezialisiert, produktionsreife, skalierbare, sichere und kostenoptimierte KI-Systeme zu entwerfen, zu entwickeln und bereitzustellen – ganz gleich, ob Sie eine RAG-Pipeline, ein traditionelles LLM oder eine hybride Architektur benötigen.
Wenn Sie prüfen, ob eine RAG-Pipeline oder ein traditionelles LLM für Ihr nächstes Projekt geeignet ist, begleitet SDH Sie von der Strategie bis zur Produktivsetzung.
SDH hilft Ihnen, den richtigen Ansatz zu wählen, das passende Nutzererlebnis zu gestalten und eine Lösung zu entwickeln, die mit Ihren Nutzern und Ihrem Unternehmen wächst.
Categories
About the author

Business Analyst bei Software Development Hub mit umfassender Erfahrung in der Geschäftsprozessanalyse und B2C&B2B-Softwareentwicklung. Verfügt über ausgeprägte soziale Kompetenzen, eine kreative und strategische Denkweise und Führungsqualitäten, die zum erfolgreichen Teammanagement und zur Projektdurchführung beitragen. Beherrscht das Management von Projekten von der Konzeption bis zu Benutzerhandbüchern, erstellt Präsentationen und nimmt als Experte am Vertrieb teil.
Share



Benötigen Sie einen Projektkostenvoranschlag?
Schreiben Sie uns, und wir bieten Ihnen eine qualifizierte Beratung.