Die Lösung: RAG-Architektur
Traditionelle KI Vs RAG-Architektur
Traditionelle KI-Systeme
RAG-Architektur
Warum Unternehmen Die RAG-Architektur Einführen
Verbesserte Genauigkeit
Echtzeit-Zugriff Auf Informationen
Niedrigere Wartungskosten
Bessere Compliance Und Governance
Wie Die RAG-KI-Architektur Funktioniert: Schritt Für Schritt
Schritt 1 — Datenaufnahme
Schritt 2 — Dokumentverarbeitung Und Chunking
Schritt 3 — Embeddings Und Vektorspeicherung
Schritt 4 — Abfrageverarbeitung Und Abruf
Schritt 5 — Antwortgenerierung Mit LLMs
Kernkomponenten Der Enterprise-RAG-Architektur
Datenquellen-Ebene
Retrieval-Ebene
Generierungs-Ebene
Orchestrierungs-Ebene
Monitoring- Und Feedback-Ebene
Vorteile Der RAG-KI-Architektur Für Unternehmen
Häufige Anwendungsfälle Der RAG-Architektur In Unternehmen
Enterprise Knowledge Management
Herausforderungen Beim Aufbau Einer RAG-KI-Architektur
Wie SDH Enterprise-Ready RAG-Architektur Aufbaut
Individuelles Architekturdesign
Sicherheitsstandards Auf Enterprise-Niveau
Leistungsoptimierung
Kontinuierliche Unterstützung Und Verbesserung
Zukünftige Trends In Der RAG-KI-Architektur
Fazit
RAG-KI-Architektur Erklärt: Ein Praktischer Leitfaden Für Geschäftsleiter

KI entwickelt sich rasant von einem „Nice-to-have“ zu einer zentralen Geschäftstechnologie und treibt alles an – vom Kundensupport bis hin zur internen Forschung. Doch wie frühe Anwender festgestellt haben, weisen Standard-KI-Modelle einen wesentlichen Fehler auf: Sie können mit großer Sicherheit falsche Antworten liefern.
Da traditionelle Large Language Models (LLMs) ausschließlich auf ihren vortrainierten Daten basieren, haben sie häufig Schwierigkeiten mit veralteten Informationen oder sogenannten „Halluzinationen“. In risikoreichen Bereichen wie Finanzen, Recht oder Gesundheitswesen ist das ein Risiko, das sich die meisten Unternehmen nicht leisten können.
Die Lösung: RAG-Architektur
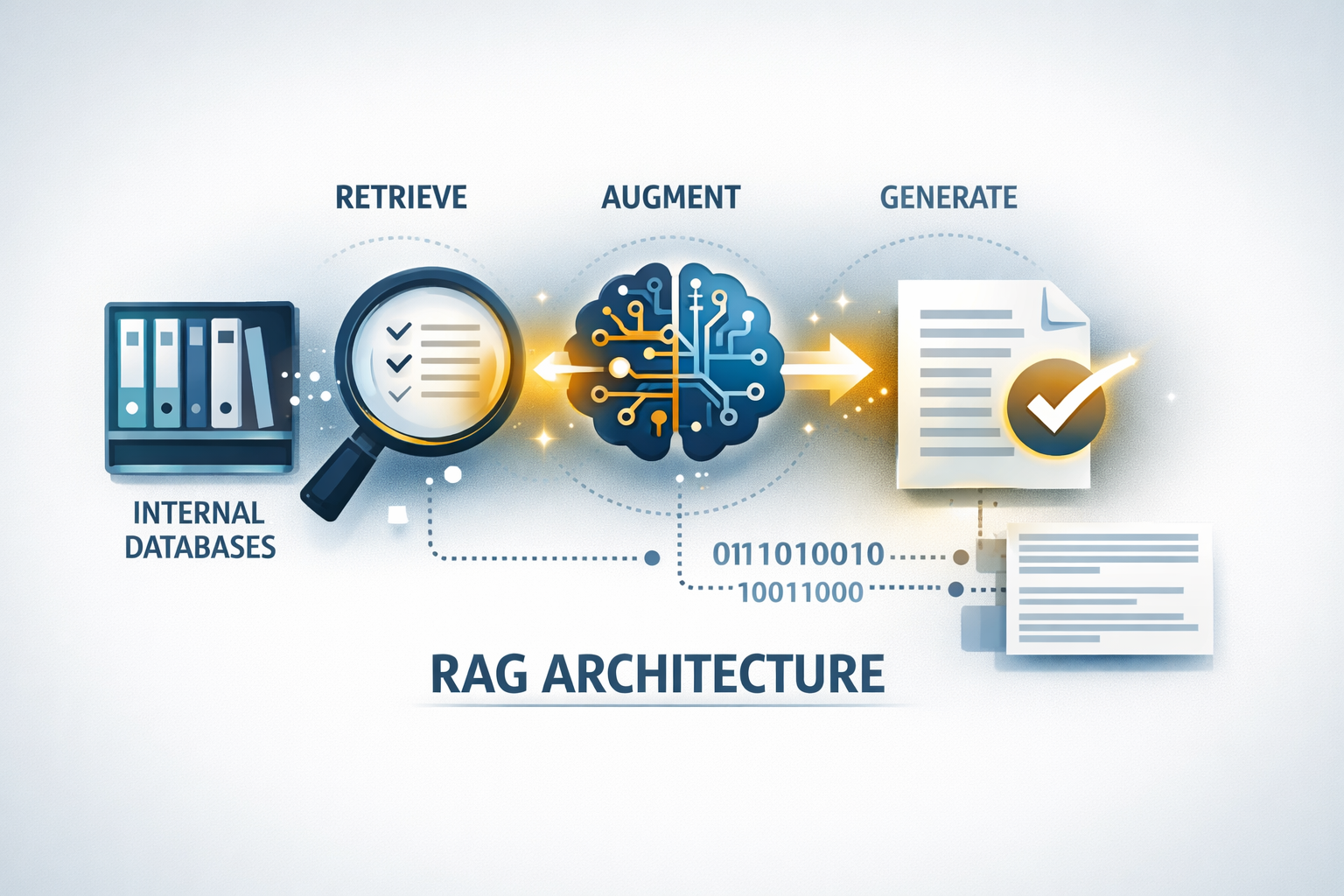
Retrieval-Augmented Generation (RAG) löst dieses Problem, indem der KI eine „lebendige“ Wissensbibliothek zur Verfügung gestellt wird. Anstatt sich auf ihr eigenes Gedächtnis zu verlassen, arbeitet ein RAG-System folgendermaßen:
- Ruft spezifische, aktuelle Fakten aus den internen Datenbanken oder Dokumenten Ihres Unternehmens ab.
- Erweitert diese Fakten mit der Argumentationsfähigkeit der KI.
- Generiert eine Antwort, die auf realen, überprüfbaren Daten basiert.
Für Geschäftsleiter bedeutet RAG, über den Hype hinauszugehen und zu zuverlässiger, kontextbewusster KI zu gelangen. Unabhängig davon, ob Sie gerade erst beginnen oder eine vollständige Einführung planen, ist das Verständnis dieser Architektur der Schlüssel zum Aufbau einer KI-Strategie, die tatsächlich für Unternehmen funktioniert.
Traditionelle KI Vs RAG-Architektur
Um die Bedeutung von RAG zu verstehen, hilft es, diese mit traditionellen KI-Modellen zu vergleichen.
Traditionelle KI-Systeme
Traditionelle Sprachmodelle werden mithilfe großer Datensätze trainiert, die zu einem bestimmten Zeitpunkt gesammelt wurden. Nach dem Training wird ihr Wissen fixiert, sofern das Modell nicht erneut trainiert wird.
Dies führt zu mehreren Einschränkungen:
- Veraltetes Wissen
- Begrenzter Zugriff auf proprietäre Unternehmensdaten
- Risiko von Halluzinationen (falsche Antworten)
- Hohe Kosten für erneutes Training
Beispielsweise kann ein traditionelles KI-Modell Änderungen nicht erkennen, wenn ein Unternehmen seine internen Richtlinien aktualisiert, sofern es nicht erneut trainiert wird — was zeitaufwendig und kostspielig sein kann.
RAG-Architektur
RAG-Systeme lösen dieses Problem, indem sie Informationen dynamisch aus vertrauenswürdigen Quellen abrufen.
Anstatt Antworten zu erraten, arbeitet das System folgendermaßen:
- Durchsucht relevante Daten
- Ruft die nützlichsten Informationen ab
- Generiert eine Antwort basierend auf realen Daten
Dadurch ist die RAG-Architektur besonders wertvoll für Unternehmen, die große Mengen an internem Wissen verwalten.
Warum Unternehmen Die RAG-Architektur Einführen
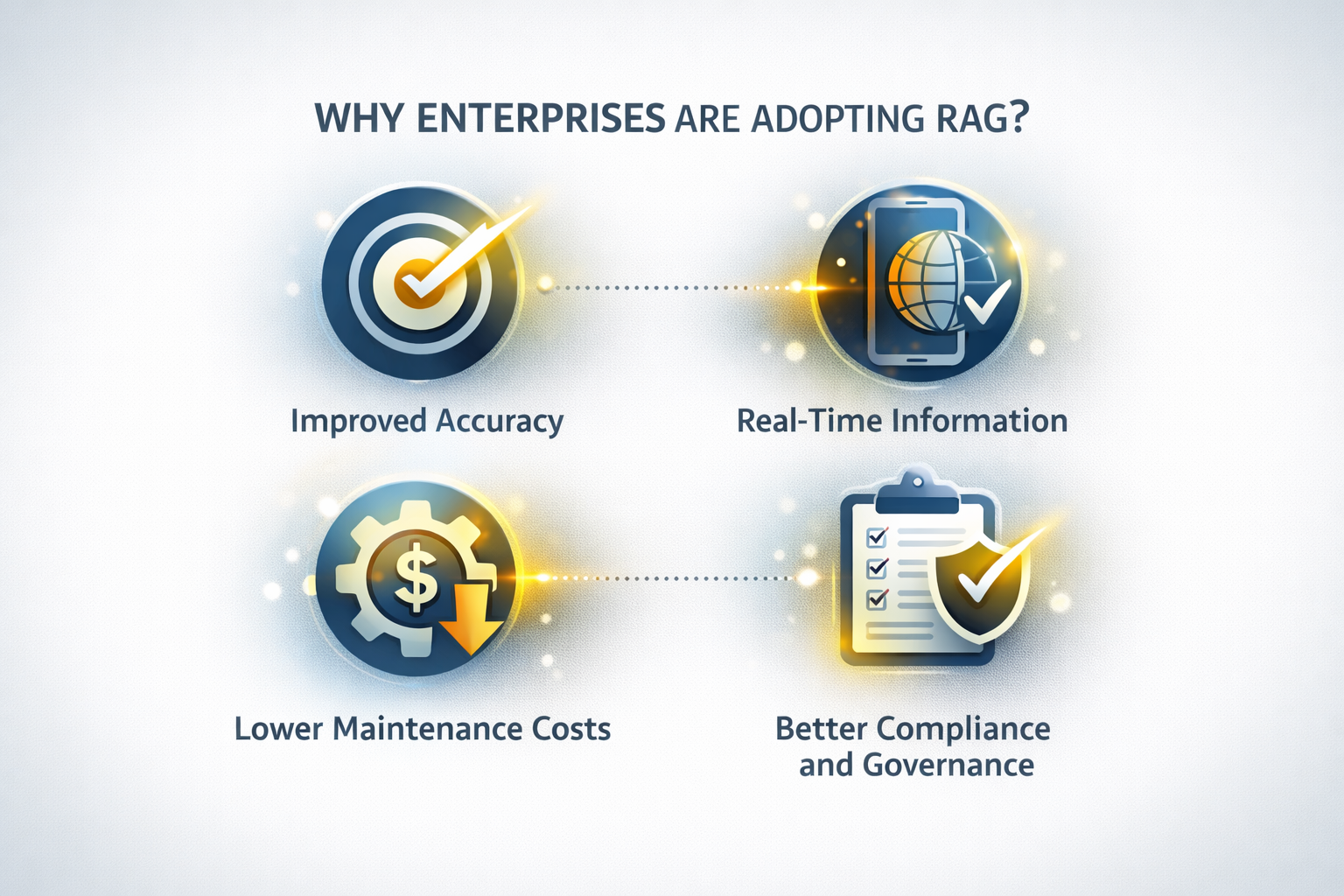
Unternehmen aus verschiedenen Branchen führen zunehmend RAG-Systeme ein, da diese einige der größten Einschränkungen traditioneller KI lösen.
Wichtige Gründe sind:
Verbesserte Genauigkeit
RAG reduziert Halluzinationen, indem Antworten auf realen Datenquellen basieren. Dies erhöht das Vertrauen in KI-generierte Antworten.
Echtzeit-Zugriff Auf Informationen
Unternehmen können RAG-Systeme verbinden mit:
- Internen Datenbanken
- Wissensdatenbanken
- Richtliniendokumenten
- Kundendaten
Dies stellt sicher, dass Antworten stets die neuesten Informationen widerspiegeln.
Niedrigere Wartungskosten
Im Gegensatz zum vollständigen erneuten Training von Modellen erfordern RAG-Systeme lediglich die Aktualisierung der Datenquelle — nicht des gesamten Modells.
Bessere Compliance Und Governance
Organisationen können genau steuern, welche Datenquellen verwendet werden, wodurch Sicherheits- und Compliance-Anforderungen leichter erfüllt werden können.
Wie Die RAG-KI-Architektur Funktioniert: Schritt Für Schritt
Die RAG-Architektur folgt einem strukturierten Workflow, der Datenabruf mit KI-Generierung kombiniert, um genaue und kontextbewusste Antworten bereitzustellen.
Schritt 1 — Datenaufnahme
Der Prozess beginnt mit der Sammlung von Daten aus Quellen wie Dokumenten, Datenbanken, Websites, CRMs, APIs und internen Wissenssystemen. Während der Aufnahme werden Daten bereinigt, standardisiert und dedupliziert, um zuverlässige Ergebnisse sicherzustellen.
Schritt 2 — Dokumentverarbeitung Und Chunking
Dokumente werden in kleinere Abschnitte, sogenannte Chunks, unterteilt, wodurch sie leichter durchsucht und verarbeitet werden können. Metadaten wie Titel, Kategorien und Daten können ebenfalls hinzugefügt werden, um die Abrufgenauigkeit zu verbessern.
Schritt 3 — Embeddings Und Vektorspeicherung
Chunks werden in Embeddings umgewandelt — numerische Darstellungen von Text, die Bedeutungen erfassen. Diese Embeddings werden in einer Vektordatenbank gespeichert, wodurch schnelle semantische Suchen basierend auf Bedeutung und nicht auf exakten Schlüsselwörtern ermöglicht werden.
Schritt 4 — Abfrageverarbeitung Und Abruf
Wenn ein Benutzer eine Frage stellt, wird diese in ein Embedding umgewandelt. Das System durchsucht die Vektordatenbank, um die relevantesten Inhalte mithilfe semantischer oder hybrider Suchmethoden abzurufen.
Schritt 5 — Antwortgenerierung Mit LLMs
Die abgerufenen Inhalte werden an ein Sprachmodell gesendet, das eine Antwort basierend auf sowohl der Benutzerfrage als auch den relevanten Daten generiert. Diese erweiterte Generierung verbessert Genauigkeit, Relevanz und Kontextverständnis und liefert zuverlässige Antworten innerhalb von Sekunden.
Kernkomponenten Der Enterprise-RAG-Architektur
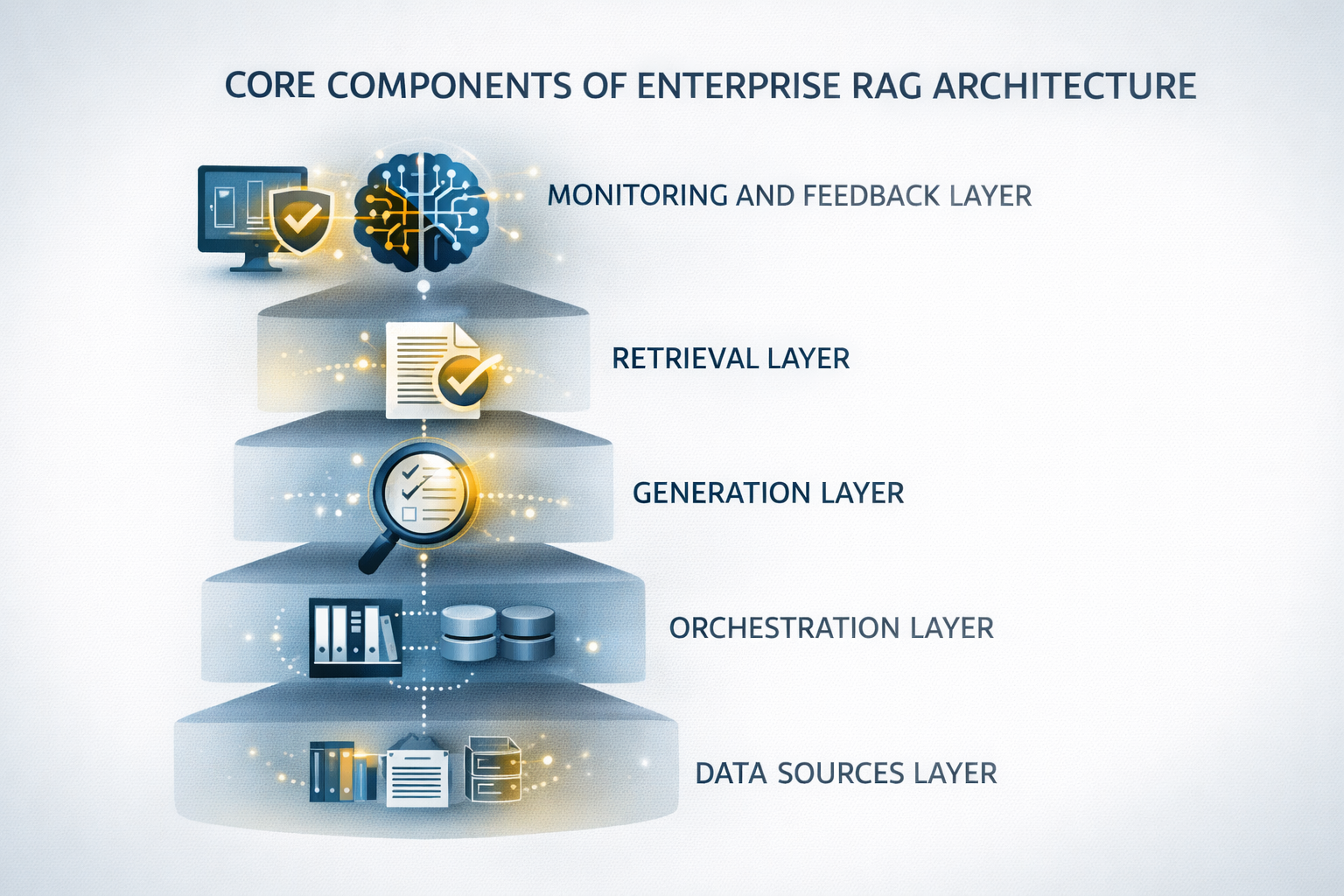
Ein erfolgreiches RAG-System ist nicht nur ein einzelnes Tool, sondern eine strukturierte Architektur, die aus miteinander verbundenen Komponenten besteht. Jede Ebene erfüllt eine spezifische Rolle, um das System zuverlässig, skalierbar und für den Unternehmenseinsatz geeignet zu machen. Das Verständnis dieser Komponenten hilft Geschäftsleitern, KI-Lösungen zu bewerten und fundierte technische Entscheidungen zu treffen.
Datenquellen-Ebene
Jedes RAG-System beginnt mit Daten. Diese Ebene definiert, woher das System seine Informationen bezieht, und führt mehrere Wissensquellen in einer einheitlichen Umgebung zusammen.
Typische Unternehmensdatenquellen umfassen:
- Interne Dokumente (PDFs, Word-Dateien, Tabellen)
- Wissensdatenbanken
- CRM- und ERP-Systeme
- Produktdokumentation
- E-Mail-Archive
- Datenbanken und APIs
- Cloud-Speichersysteme
Beispielsweise könnte ein Finanzdienstleistungsunternehmen Compliance-Dokumente, Kundenrichtlinien, Investmentberichte und Marktforschungsdaten verbinden. Dies ermöglicht es Mitarbeitern, Fragen in natürlicher Sprache zu stellen und genaue Antworten aus vertrauenswürdigen Quellen zu erhalten.
Die Qualität dieser Datenquellen wirkt sich direkt auf die Systemleistung aus. Gut strukturierte und organisierte Daten führen zu zuverlässigeren KI-Antworten.
Retrieval-Ebene
Die Retrieval-Ebene findet die relevantesten Informationen aus den verfügbaren Datenquellen. Dies ist einer der kritischsten Teile des Systems.
Anstelle manueller Suchen verwendet diese Ebene Techniken wie:
- Semantische Suche
- Vektorähnlichkeitssuche
- Hybride Suche (Schlüsselwörter + Bedeutung)
- Ranking-Algorithmen
Diese Methoden ermöglichen es dem System, relevante Informationen zu finden, selbst wenn exakte Begriffe nicht verwendet werden. Beispielsweise kann eine Frage zu Richtlinien für Remote-Arbeit dennoch ein Dokument mit dem Titel „Flexible Arbeitsplatzrichtlinien“ abrufen.
Diese Fähigkeit verbessert die Produktivität erheblich, insbesondere in großen Organisationen mit umfangreicher Dokumentation.
Generierungs-Ebene
Nachdem relevante Inhalte abgerufen wurden, erzeugt die Generierungs-Ebene die endgültige Antwort mithilfe eines Large Language Models (LLM).
Das Modell:
- Versteht die Frage des Nutzers
- Analysiert die abgerufenen Inhalte
- Generiert eine strukturierte Antwort
Anstatt Antworten zu erfinden, nutzt das Modell die abgerufenen Informationen als primäre Quelle. Dieser Ansatz reduziert Halluzinationen, verbessert die Genauigkeit und stärkt das Vertrauen in KI-generierte Ergebnisse.
Zuverlässige Antworten sind in Unternehmensumgebungen entscheidend, in denen Genauigkeit direkten Einfluss auf Entscheidungen hat.
Orchestrierungs-Ebene
Die Orchestrierungs-Ebene verwaltet den Workflow des gesamten RAG-Systems. Sie koordiniert alle Komponenten, sodass sie reibungslos zusammenarbeiten.
Typische Orchestrierungsaufgaben umfassen:
- Verwaltung von Such-Workflows
- Auswahl von Retrieval-Strategien
- Formatierung von Prompts
- Weiterleitung von Anfragen
- Verarbeitung von Systemlogik und Fehlern
Ohne Orchestrierung würden Systemkomponenten unabhängig voneinander arbeiten, was zu inkonsistenter Leistung führen würde. Moderne Enterprise-RAG-Systeme sind auf Orchestrierungs-Frameworks angewiesen, um Stabilität und Skalierbarkeit sicherzustellen.
Monitoring- Und Feedback-Ebene
Ein produktionsreifes RAG-System erfordert kontinuierliches Monitoring. Diese Ebene verfolgt die Systemleistung und hilft Teams, die Ergebnisse im Laufe der Zeit zu verbessern.
Wichtige Kennzahlen umfassen:
- Antwortgenauigkeit
- Abfragelatenz
- Retrieval-Qualität
- Systemverfügbarkeit
- Nutzerfeedback
Organisationen implementieren häufig Feedback-Schleifen, die es Nutzern ermöglichen, Antworten zu bewerten, Fehler zu melden und Verbesserungen vorzuschlagen. Dieses Feedback hilft dabei, das System zu optimieren und eine hohe Leistungsqualität aufrechtzuerhalten.
Im Laufe der Zeit wird Monitoring zu einem der wertvollsten Werkzeuge, um zuverlässige und effiziente KI-Operationen aufrechtzuerhalten.
Vorteile Der RAG-KI-Architektur Für Unternehmen

Die RAG-Architektur bietet messbare Vorteile über Abteilungen und Branchen hinweg. Diese Vorteile gehen weit über einfache Automatisierung hinaus – sie beeinflussen Produktivität, Entscheidungsfindung und operative Effizienz.
- Verbesserte Genauigkeit Und Zuverlässigkeit
- Echtzeit-Zugriff Auf Wissen
- Erhöhte Entscheidungsfähigkeit
- Kosteneffizienz Im Vergleich Zum Modelltraining
Häufige Anwendungsfälle Der RAG-Architektur In Unternehmen
Die RAG-Architektur ist hochflexibel und unterstützt eine breite Palette von Geschäftsanwendungen. Organisationen in verschiedenen Branchen nutzen bereits RAG-Systeme, um Arbeitsabläufe zu verbessern und Kundenerlebnisse zu optimieren.
Enterprise Knowledge Management
Große Organisationen haben oft mit fragmentierten Informationen zu kämpfen.
Mitarbeiter verbringen wertvolle Zeit damit, Antworten über mehrere Systeme hinweg zu suchen.
RAG-gestützte Wissensplattformen zentralisieren Informationen und ermöglichen es Mitarbeitern, Fragen in natürlicher Sprache zu stellen.
Beispielhafte Abfragen:
- "Was ist der Onboarding-Prozess für neue Mitarbeiter?"
- "Wie gehen wir mit Produktretouren um?"
- "Wo finde ich die Richtlinien zur Cybersicherheit?"
Anstatt manuell zu suchen, erhalten Mitarbeiter sofortige Antworten.
Dies verbessert die Produktivität und verkürzt die Einarbeitungszeit für neue Mitarbeiter.
Herausforderungen Beim Aufbau Einer RAG-KI-Architektur
Obwohl die RAG-Architektur leistungsstarke Funktionen bietet, ist der Aufbau eines produktionsbereiten Systems nicht ohne Herausforderungen. Organisationen, die diese Risiken frühzeitig verstehen, sind besser darauf vorbereitet, zuverlässige und skalierbare Lösungen umzusetzen.
Die meisten Implementierungsherausforderungen fallen in vier zentrale Bereiche:
- Datenqualität und -aufbereitung
- Latenz- und Leistungsprobleme
- Sicherheits- und Compliance-Anforderungen
- Integration mit bestehenden Systemen
Eine erfolgreiche Integration erfordert sorgfältige Planung und fundierte technische Expertise.
Organisationen, die in flexible Integrationsstrategien investieren, erleben reibungslosere Implementierungsprozesse und weniger Störungen.
Wie SDH Enterprise-Ready RAG-Architektur Aufbaut
Der Aufbau eines zuverlässigen RAG-Systems erfordert eine strukturierte Methodik, starke Ingenieursarbeit und kontinuierliche Optimierung. Organisationen, die mit erfahrenen Teams zusammenarbeiten, erhalten Zugang zu bewährten Frameworks und skalierbaren Lösungen.
Individuelles Architekturdesign
Jede Organisation hat einzigartige Bedürfnisse. Der Prozess beginnt mit der Analyse von Workflows, der Identifizierung von Datenquellen und der Definition von Leistungszielen, um sicherzustellen, dass das System mit den realen Geschäftsabläufen übereinstimmt.
Sicherheitsstandards Auf Enterprise-Niveau
Sicherheit ist in jede Schicht integriert – durch Zugriffskontrollen, sichere Datenpipelines, Verschlüsselung und Compliance-fähige Workflows, die sensible Informationen schützen.
Leistungsoptimierung
Kontinuierliches Tuning verbessert Abrufgeschwindigkeit, Abfrageeffizienz und Infrastruktur-Skalierbarkeit, um zuverlässige Leistung bei wachsenden Arbeitslasten zu gewährleisten.
Kontinuierliche Unterstützung Und Verbesserung
Fortlaufendes Monitoring, Datenaktualisierungen, Genauigkeitsverbesserungen und Erweiterung von Funktionen stellen sicher, dass das System langfristigen Nutzen liefert.
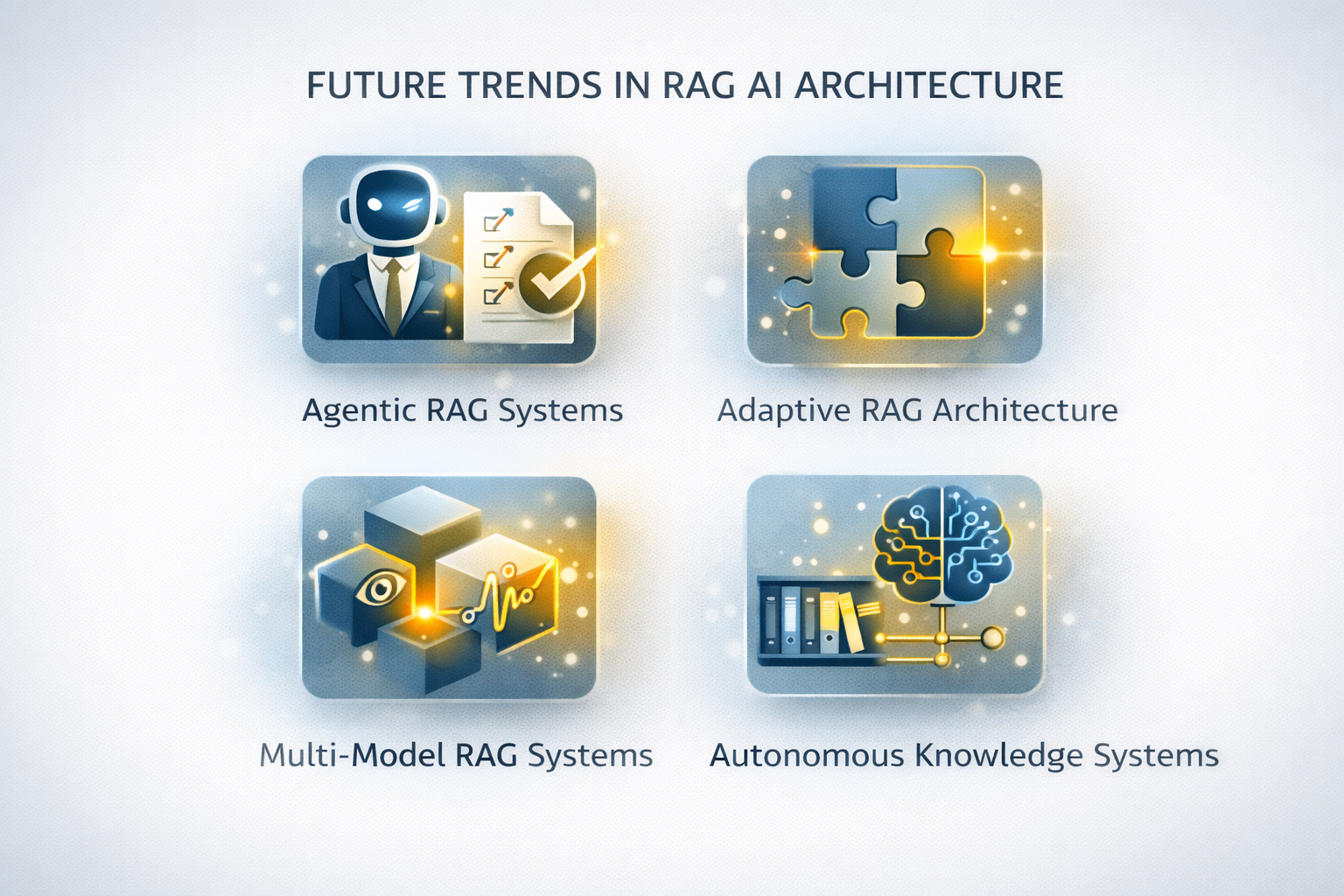
Zukünftige Trends In Der RAG-KI-Architektur
Die RAG-Technologie entwickelt sich weiterhin schnell. Mehrere aufkommende Trends prägen die Zukunft der Enterprise-KI-Architektur.
Organisationen, die über diese Trends informiert bleiben, sind besser positioniert, innovative Lösungen zu übernehmen.
- Agentische RAG-Systeme
- Adaptive RAG-Architektur
- Multi-Modell RAG-Systeme
- Autonome Wissenssysteme
Fazit
Die RAG-KI-Architektur transformiert Enterprise-KI, indem sie Echtzeit-Datenabruf mit Sprachgenerierung kombiniert, um genauere und zuverlässigere Antworten zu liefern.
Organisationen, die gut gestaltete RAG-Systeme implementieren, verbessern Produktivität, Wissensmanagement und Entscheidungsfindung. Der langfristige Erfolg hängt jedoch von hoher Datenqualität, Sicherheit, Leistung und Skalierbarkeit ab. Unternehmen, die in maßgeschneiderte RAG-Architektur investieren, sind besser aufgestellt, um wettbewerbsfähig zu bleiben, während sich KI weiterhin entwickelt.
Categories
About the author

Business Analyst bei Software Development Hub mit umfassender Erfahrung in der Geschäftsprozessanalyse und B2C&B2B-Softwareentwicklung. Verfügt über ausgeprägte soziale Kompetenzen, eine kreative und strategische Denkweise und Führungsqualitäten, die zum erfolgreichen Teammanagement und zur Projektdurchführung beitragen. Beherrscht das Management von Projekten von der Konzeption bis zu Benutzerhandbüchern, erstellt Präsentationen und nimmt als Experte am Vertrieb teil.
Share
Neueste Beiträge



Benötigen Sie einen Projektkostenvoranschlag?
Schreiben Sie uns, und wir bieten Ihnen eine qualifizierte Beratung.