Anwendungen zur Verarbeitung natürlicher Sprache

Die natürliche Sprache ist eine der wichtigsten Methoden der menschlichen Kommunikation. Sie besteht aus Wörtern und wird mit Hilfe von Text, Sprache und Gesten ausgedrückt. Die Gesten stehen in diesem Beitrag nicht im Vordergrund, daher werden wir mit Text und Sprache fortfahren. In unserer digitalisierten Welt werden wir sehr ermutigt, mit Geräten zu kommunizieren, und das Lesen dieses Beitrags ist in der Tat eine Kommunikation per Text. All diese Faktoren haben dazu geführt, dass NLP in die vorderste Reihe der ML / DS-Themen gerückt ist. Was wissen wir also über NLP?
Was ist NLP?
Natural Language Processing (NLP) is a sub-field of artificial intelligence that involves computers understanding texts and spoken words the same way we humans do. This area is very valuable for companies to process and gain insights from huge amounts of data from emails, social media, chats, surveys, etc. NLP is a technology that is already being used by many companies, and we will introduce some of them in the following sections.
Sentiment-Analyse

Die Art und Weise, wie wir sprechen, wird oft von Phrasen, Gefühlen oder Sarkasmus begleitet, die die wörtliche Bedeutung von Wörtern verkomplizieren. Diese Faktoren treten häufig in den sozialen Medien auf und sind für Computer nur schwer zu verstehen. Hier kommt NLP, vor allem seine Untergruppe NLU (Natural Language Understanding), ins Spiel. Mit NLU können Computer zwischen den Stimmungen unterscheiden und den Ton des Textes erkennen. Die Stimmungsanalyse ist eine NLP-Methode zur Identifizierung der Positivität, Negativität oder Neutralität von Daten. Unternehmen führen häufig Stimmungsanalysen von Textdaten durch, um die Wahrnehmung ihrer Marken und Produkte in Kundenrezensionen zu verfolgen und ihren Zielmarkt besser zu verstehen.
Es gibt mehrere Möglichkeiten, NLP für die Sentiment-Analyse zu nutzen. Diese sind:
- Regelbasiert - verwendet einige NLP-Techniken wie Stemming, Tokenisierung, Part-of-Speech-Tagging. Funktioniert wie folgt: Definieren Sie die Wörter für jede Gruppe (negativ/positiv), zählen Sie die Anzahl jeder Wortgruppe, die in einem Satz vorkommt. Je nach Anzahl der einzelnen Stimmungsgruppen wird festgestellt, ob der Satz positiv oder negativ ist. Bei Gleichstand wird neutral zurückgegeben. Der regelbasierte Ansatz kann jedoch bis zu einem sehr komplexen System reichen.
- Automatisch - hier wird ML eingesetzt. Die Stimmungsanalyse ist normalerweise ein Klassifizierungsproblem. Wir haben gekennzeichnete Daten und versuchen, anhand der Daten von Sätzen mit Bewertungen/Kommentaren/Feedbacks usw. die richtigen Stimmungen zu finden. Der Schlüsselaspekt dieses Ansatzes ist eine angemessene Merkmalsextraktion und die Vorbereitung der Merkmalsvektoren. Hierfür verwenden wir Bag-of-Words, Word Embeddings, TF-IDF.
- Hybrid - Kombination der oben genannten Techniken. Führt in der Regel zu genaueren Ergebnissen.
Bleiben Sie dran für die Implementierung der Airline Sentiment Analysis.
Übersetzung von Sprachen
Jeder hat schon einmal das Bedürfnis gehabt, etwas sehr schnell zu übersetzen. Sei es Google Translate oder eine andere ähnliche Anwendung. Solche Anwendungen beruhen auf einer Technik, die als maschinelle Übersetzung bezeichnet wird. Sie ist definiert als ein Prozess der automatischen Umwandlung von Text von einer Sprache in eine andere, ohne dass die Bedeutung verloren geht. Im Vergleich zu den Zeiten, in denen Übersetzungsanwendungen auf der Grundlage von Wörterbüchern erstellt wurden, was ein regelbasierter Ansatz für ein Problem ist, verwendet der aktuelle, hochmoderne Ansatz der maschinellen Übersetzung (NMT) ein neuronales Netzwerk, um die Wahrscheinlichkeit von Wörtern vorherzusagen. Der größte Vorteil von NMT im Vergleich zu SMT (statistische maschinelle Übersetzung) und regelbasierter Übersetzung ist die hohe Geschwindigkeit und die Fähigkeit, Wörter zu lernen und sie bei Bedarf wiederzuverwenden.
Automatische Korrektur und Vorhersage
Heutzutage gibt es mehrere Programme, die uns helfen können, Rechtschreib- und Grammatikfehler in unseren E-Mails, Nachrichten und anderen Dokumenten zu vermeiden, indem sie die Grammatik und Rechtschreibung des eingegebenen Textes überprüfen (z. B. Grammarly). NLP ist eine wichtige Technologie für diese Anwendungen. Diese Programme verfügen über eine breite Palette von Funktionen, darunter die Fähigkeit, Synonyme vorzuschlagen, Grammatik- und Rechtschreibfehler zu korrigieren, Wörter umzuformulieren, um sie klarer zu formulieren, und sogar den impliziten Tonfall einer Aussage des Benutzers einzuschätzen. Eine weitere NLP-Funktion mit der Bezeichnung "automatische Vorhersage" schlägt eine automatische Textvorhersage für den Text vor, den wir bereits zu schreiben begonnen haben. Dies hilft dem Benutzer, Zeit zu sparen und seine Arbeit zu vereinfachen. Dies sind die Schritte zur Erstellung solcher Modelle:
- Identifizieren Sie das falsch geschriebene Wort.
- Suche nach Zeichenfolgen, die in N-Edit-Abstand zum falschen Wort stehen.
- Filterring.
- Sortierung nach Wortwahrscheinlichkeiten.
- Wählen Sie den besten Fall.
Bei der Textvorhersage werden N-Gramme auf der Grundlage der Wahrscheinlichkeit ihres Vorkommens verwendet. Kontinuierliche Gruppen von Wörtern, Phrasen oder anderen Symbolen, die in einem Dokument vorkommen, werden als N-Gramme bezeichnet.
Gezielte Werbung

Wenn Sie jemals in einem Online-Shop nach einem Produkt oder Gegenstand gesucht haben, werden Sie auf anderen Websites häufig auf Werbung für solche Dinge und andere relevante Produkte stoßen. Gezielte Online-Werbung dieser Art wird als gezielte Werbung bezeichnet und mit Hilfe von NLP durchgeführt.
Der wesentliche Bestandteil der gezielten Werbung ist das Keyword-Matching. Nur wer nach einem Begriff sucht, der demjenigen ähnlich ist, mit dem die Werbung verknüpft wurde, sieht die Anzeigen, die mit einem bestimmten Wort oder Ausdruck verbunden sind. Das reicht natürlich nicht aus; es werden auch andere Faktoren berücksichtigt, z. B. die anschließend besuchten Websites und die Seiten, für die sie sich interessiert haben, um ihnen die wesentlichen Anzeigen von Produkten zu zeigen, die sie interessieren könnten.
Da die Werbung nur den Kunden angezeigt wird, die wirklich an dem Produkt interessiert sind, was anhand ihres Online-Verhaltens beurteilt wird, haben viele Unternehmen sehr davon profitiert und eine erhebliche Menge Geld gespart.
Chatbots

Für mich persönlich sind Chatbots heutzutage ein fester Bestandteil der meisten Unternehmen, Regierungsseiten und Online-Dienste. Sie sind buchstäblich überall zu finden. Was unterscheidet also einen KI-gesteuerten Bot von einem regelbasierten Bot?
Wir bezeichnen die Mehrheit der gängigen Bots als "regelbasierte" Bots. Sie halten sich sorgfältig an die Konversationsrichtlinien, die ihr Autor festgelegt hat. Wenn ein Benutzer einen bestimmten Befehl eingibt, gibt ein regelbasierter Bot automatisch eine vorformulierte Antwort. Ein herkömmlicher Bot hingegen kann dem Benutzer nur schwer wertvolle Informationen geben, wenn diese Richtlinien nicht befolgt werden. Die Anpassungsfähigkeit, die ein wesentlicher Bestandteil menschlicher Dialoge ist, fehlt. Das sind die Dinge, die einen KI-Chatbot so besonders und wertvoll machen:
- Natürliche Sprache verstehen.
- Die Art der Kommunikation ist nicht nur ein Q/A.
- Kontinuierliche Verbesserung.
Um einen Chatbot darauf zu trainieren, natürliche Sprache zu verstehen, benötigen Sie eine Menge Daten. Zahlreiche Quellen, darunter soziale Medien, Foren und Kundendienstprotokolle, können genutzt werden, um diese Informationen zu erhalten. Um vielen Umständen gerecht zu werden, müssen die Daten diversifiziert und beschriftet werden.
In einem nächsten Schritt müssen Sie die gesammelten Daten vorverarbeiten. Die Tokenisierung des Textes in kleinere Bits, die Bereinigung und Normalisierung der Daten sind die entscheidenden Schritte, die durchgeführt werden müssen.
- Textnormalisierung - Aufrechterhaltung der Einheitlichkeit der Daten, Umwandlung von Text in Kleinbuchstaben, Entfernen von Satzzeichen, Symbolen usw.
- Tokenisierung - Zerlegung des Textes in kleinere Teile, z. B. in Wörter oder Sätze.
- Entfernen von Stoppwörtern - Begriffe wie "der", "ist" und "und" aus dem Text, die dem Datensatz keine wesentliche Bedeutung verleihen.
- Lemmatisierung - reduziert die Dimensionalität der Daten.
- Part-of-Speech-Tagging - Identifizierung der grammatikalischen Rolle jedes Worts im Text, z. B. als Substantiv, Verb oder Adjektiv.
Dann ist es wichtig zu verstehen, welche NLP-Technik für Ihre Geschäftsanforderungen geeignet ist. Das kann eine Sentiment-Analyse, ein auf maschinellem Lernen basierender Ansatz, ein Schlüsselwort-Matching-System oder ein Sprachmodell sein.
ChatGPT und NLP
Dieser Blogpost sollte nicht enden, ohne den Trend ChatGPT zu erwähnen. ChatGPT ist ein hochmodernes Modell für die Verarbeitung natürlicher Sprache (NLP), das von OpenAI entwickelt wurde. Es handelt sich dabei um eine Variante des bekannten GPT-3-Modells (Generative Pertained Transformer 3), das auf einer riesigen Menge von Textdaten (~ 570 GB Datensätze, darunter Webseiten, Bücher und andere Quellen) trainiert wurde, um menschenähnliche Antworten zu erzeugen. Es ist eine Erweiterung der Large Language Model (LLM)-Klasse von Modellen für maschinelles Lernen zur Verarbeitung natürlicher Sprache. LLMs nehmen riesige Mengen von Textinformationen auf und leiten daraus Assoziationen zwischen Wörtern im Text ab. Da sich die Computerleistung in den letzten Jahren verbessert hat, wurden diese Modelle erweitert. LLMs werden immer leistungsfähiger, je größer ihre Eingabedatensätze und der Parameterraum werden. Sprachmodelle analysieren den Text in den Daten, um die Wahrscheinlichkeit des nachfolgenden Wortes zu berechnen. Zum Trainieren von Sprachmodellen werden verschiedene probabilistische Methoden verwendet. Das GPT-3 ist eine Familie von Modellen und nicht ein einzelnes Modell. Die Anzahl der trainierbaren Parameter variiert zwischen den Mitgliedern der gleichen Modellfamilie. Ein ziemlich leistungsfähiges Werkzeug mit derzeit noch ausreichenden Beschränkungen. Ich freue mich darauf, GPT4 zu erforschen und zu testen...
Sentiment-Analyse - Beispiel-Codes
Versuchen wir, eine Sentiment-Analyse für den Datensatz einer Fluggesellschaft durchzuführen.
Oben sehen wir die Hauptimporte Natural Language Toolkit - eine Sammlung von Bibliotheken für NLP und Stoppwörter - eine Sammlung von Wörtern, die keine Bedeutung für einen Satz haben und daher aus dem Datensatz entfernt werden sollten.

Airline sentiment dataset

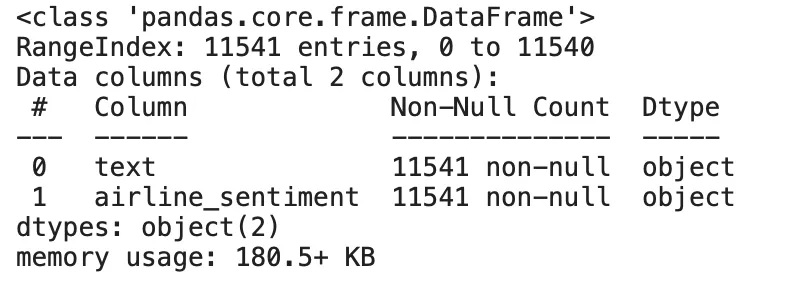
Überprüft, dass keine Nullwerte in unserem Datensatz vorhanden sind.
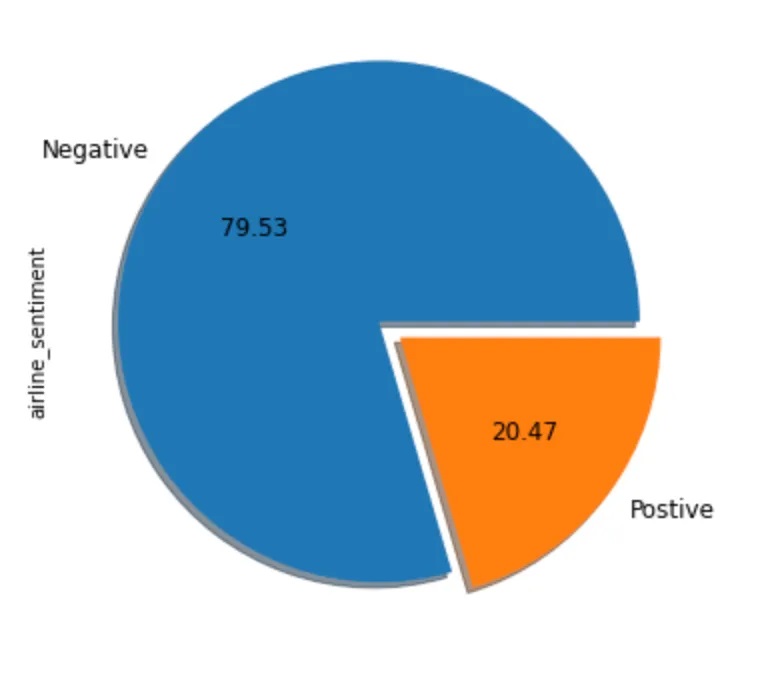
Distribution of tweets by sentiments in dataset
Es ist offensichtlich, dass wir unausgewogene Daten zu den negativen Tweets haben. Daher müssen wir Techniken verwenden, um mit unausgewogenen Daten umzugehen. SMOTE ist eine der Techniken, die synthetische Daten generiert, um die Anzahl der positiven Fälle in ausgewogener Weise zu erhöhen.
Lemmatisieren - eliminiert alle Suffixe und lässt nur die Wurzel des Wortes übrig.
Das obige Codeschnipsel ist nur eine schnelle und einfache Bereinigung des Textes, bei der Stoppwörter, Zahlen und Sonderzeichen aus der Textspalte entfernt werden.
Die Spalte "Airline Sentiment" war ursprünglich eine Spalte vom Typ "String" und muss daher konvertiert und numerisch gemacht werden.
Converting label from String to int
Nun müssen wir das Gleiche für den bereinigten Textdatensatz tun. Wir werden den TF-IDF-Vektorisierer verwenden, der die Wörter in Vektoren umwandelt, indem er nicht nur die Anzahl des Auftretens eines Wortes, sondern auch die Bedeutung dieses Wortes berücksichtigt.
Nun zurück zum Problem der unausgewogenen Daten, das wir noch nicht gelöst haben.
Nun, da wir mit der Vorbereitung des Datensatzes fertig sind, können wir die letzten Schritte des Trainings des Modells und des Testens der Ergebnisse durchführen.
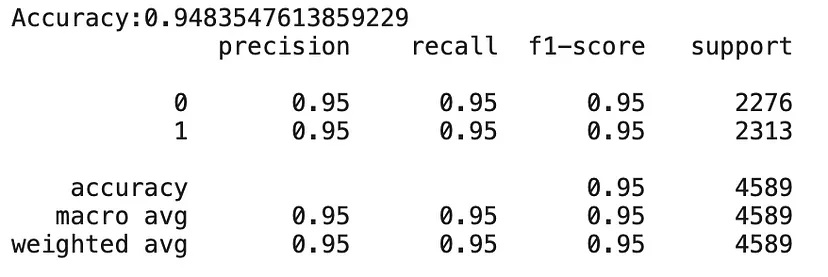
Die Überwachung der Rückmeldungen der Kunden und die Einholung ihrer Meinungen helfen den Unternehmen, die Qualität ihrer Produkte und Dienstleistungen zu verbessern. Dies führt zu höheren Umsätzen. Dieses Modell wäre noch viel wertvoller, wenn wir Daten über einen längeren Zeitraum erhalten könnten.
Software Development Hub ist ein Team von Gleichgesinnten mit umfangreicher Erfahrung in den Bereichen Softwareentwicklung, Web- und Mobile-Engineering sowie kundenspezifische Softwareentwicklung für Unternehmen. Wir schaffen sinnvolle Produkte, die sich an den Geschäftszielen des Kunden orientieren. Hauptbereiche der Entwicklung: digitale Gesundheit, Buchhaltung, Bildung.
Categories
Share
Neueste Beiträge



Benötigen Sie einen Projektkostenvoranschlag?
Schreiben Sie uns, und wir bieten Ihnen eine qualifizierte Beratung.