Data Lakes und Analysen auf AWS
Was ist ein Data Lake? Mit den jüngsten technologischen Fortschritten gibt es eine große Nachfrage nach einer Lösung für die Datenspeicherung und -analyse, die eine größere Agilität und Flexibilität als herkömmliche Datenverwaltungssysteme bietet.
An dieser Stelle kommen Data Lakes für die meisten AWS-Kunden ins Spiel. Da er es Unternehmen ermöglicht, zahlreiche Datentypen aus einer Vielzahl von Quellen zu verarbeiten und diese Daten, sowohl strukturierte als auch unstrukturierte, in einem zentralen Repository zu speichern, ist ein Data Lake eine neuartige und häufigere Methode zur Speicherung und Analyse von Daten. Sie können verschiedene Arten von Analysen durchführen, von Dashboards und Visualisierungen bis hin zu Big-Data-Verarbeitung, Echtzeit-Analysen und maschinellem Lernen, um bessere Entscheidungen zu treffen, ohne Ihre Daten zuvor zu strukturieren. Mit anderen Worten: Die Daten bleiben in ihrem ursprünglichen Format erhalten und werden mit Tools für die Analyse, Abfrage und Verarbeitung versehen.
Architektur
Lassen Sie uns nun über die Interna des Data Lake sprechen. Die Architektur ist im Wesentlichen eine Sammlung von Tools, die zur Erstellung und Operationalisierung eines solchen spezifischen Datenansatzes verwendet werden. Sie beginnt mit Tools für die Ereignisverarbeitung, geht über Ingestion und Transformationspipelines bis hin zu den Analyse- und Abfragetools. Je nach Geschäftsanforderungen gibt es viele verschiedene Kombinationen dieser Tools, um einen kompletten Data Lake aufzubauen. In den folgenden Abschnitten werden wir einige der möglichen Kombinationen vorstellen.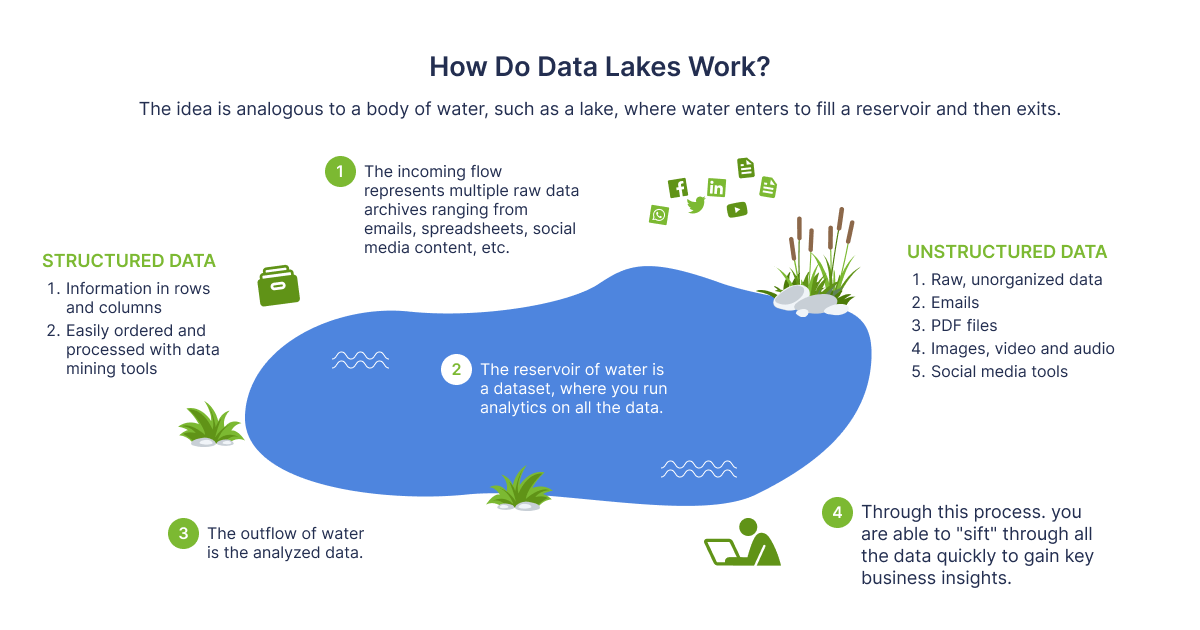
Rehan van der Merwe — “ How do Data Lakes work?”
Wenn es darum geht, die Daten in einem See funktionsfähig zu machen, benötigen Sie gut definierte Prozesse zur Systematisierung und Sicherung dieser Daten. Lake Formation ist ein Service mit einer Reihe von Mechanismen, die Ihnen helfen, die Governance Ihrer Daten zu implementieren und die Zugriffskontrollen für den Data Lake einzurichten. Diese Funktion ist sehr wichtig für die Durchführung von Analysen und maschinellem Lernen auf Ihren Daten.
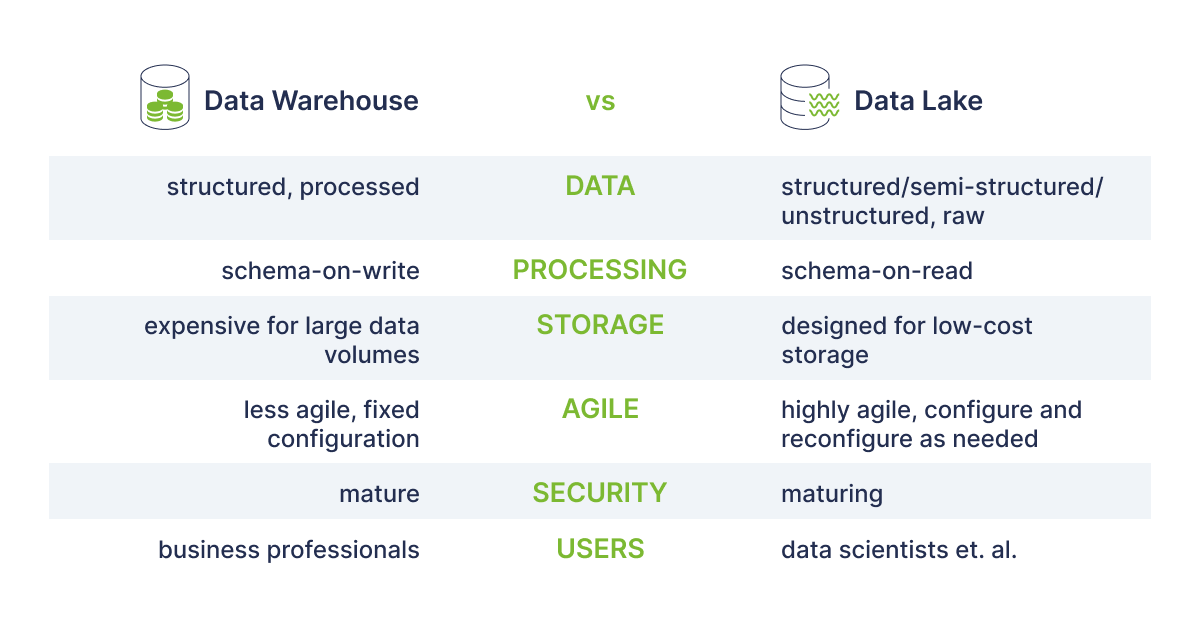
Im Allgemeinen benötigt ein typisches Unternehmen je nach den Anforderungen sowohl ein Data Warehouse als auch einen Data Lake, da beide verschiedene Zwecke und Anwendungsfälle erfüllen. Der Hauptunterschied zwischen Data Warehouse und Data Lake besteht darin, dass ein Data Warehouse eine Datenbank ist, die für die Analyse relationaler Daten aus Anwendungen und Transaktionssystemen konzipiert ist, während der Data Lake, wie bereits erwähnt, sowohl relationale Daten aus Geschäftsanwendungen als auch nicht-relationale Daten aus sozialen Medien und IoT-Geräten enthält.
Damit die Daten im Data Warehouse als "einzige Quelle der Wahrheit" dienen können, auf die sich die Verbraucher verlassen können, müssen die Informationen bereinigt, verbessert und umgewandelt werden. Beim Data Lake hingegen werden die Struktur oder das Schema der Daten bei der Erfassung nicht festgelegt. Dies bedeutet, dass alle Ihre Daten ohne sorgfältige Planung gespeichert werden können. In der nachstehenden Tabelle sind die wichtigsten Unterschiede zwischen den beiden Systemen aufgeführt.
Vorteile und Herausforderungen
Wie jeder andere Service hat auch Data Lakes auf AWS seine Vor- und Nachteile. In diesem Abschnitt werde ich versuchen, die Vorteile und einige Herausforderungen bei der Nutzung von Data Lakes in AWS aufzulisten.
Vorteile
- Data Lakes ermöglichen den Import beliebiger Datenmengen, die in Echtzeit anfallen können.
- Data Lakes fungieren als einzige Quelle der Wahrheit für jeden Datentyp. Dies bedeutet, dass es nicht nötig ist, mehrere Quellen mit spezifischen ETL-Tools zu verbinden.
- Die Automatisierung auf jeder Ebene ist der Hauptvorteil eines Data Lakes und der Infrastruktur, die ihn unterstützt. Die Aktualisierung von Datensätzen kann technisch gesehen jede Minute erfolgen, und einige davon können in Data Lakes sogar fast sofort durchgeführt werden. Einmal eingerichtet, getestet und in Betrieb genommen, verändert diese Automatisierung das Spiel. Außerdem zeigt sie an, dass die Datenaktualisierung ohne Auswirkungen auf die transaktionalen Systeme erfolgt.
- In Data Lakes liefert das automatisierte Laden von Daten in Verbindung mit der Bereinigung und Harmonisierung den Geschäftsanwendern fast sofort Erkenntnisse. Fast alle Teams, die von administrativen Richtlinien abhängig sind, haben unbegrenzten Zugriff auf Daten. In den meisten Fällen haben die Teams Datenlücken übersprungen, um mit Hilfe von Visualisierungstools zu Erkenntnissen in Echtzeit zu gelangen. Die transaktionalen Systeme können mit diesen Erkenntnissen aktualisiert werden, um die Entscheidungsfindung zu beschleunigen und zu verbessern.
Herausforderungen
Da es keine Kontrolle über die Rohdaten gibt, die in einem Data Lake Design gespeichert werden, ist dies der grundlegende Nachteil. Ein Data Lake muss über gut definierte Prozesse für die Katalogisierung und Sicherung von Daten verfügen, um die Daten funktionsfähig zu machen, andernfalls kann er in einem "Datensumpf" enden. Data Lakes müssen Governance, semantische Konsistenz und Zugriffskontrollen beinhalten, um den Anforderungen unterschiedlicher Zielgruppen gerecht zu werden.
Anwendungsfälle
1.Siemens bewältigt 60.000 Cyber-Bedrohungen pro Sekunde mit AWS Machine Learning
Siemens CDC verwendet Amazon SageMaker für die Datenbeschriftung, die Vorbereitung und das Training von ML-Algorithmen. Es verwendet Data Lake auf Basis von Amazon S3 (6 TB Protokoll pro Tag), AWS Glue - ETL-Service und AWS Lambda - ein serverloser Service, der Code als Reaktion auf Ereignisse ausführt. Insgesamt werden 60.000 potenziell kritische Ereignisse pro Sekunde von der serverlosen AWS-Cyberbedrohungsanalyseplattform verarbeitet, die von weniger als einem Dutzend Mitarbeitern erstellt und betrieben wird.
2. Depop wird vom Datensumpf zum Datensee
Depop - eine Social-Shopping-Anwendung mit Tausenden von Nutzern (London, UK). Diese Nutzer beteiligen sich an einer Vielzahl von app-bezogenen Aktivitäten, wie z. B. Folgen, Nachrichtenübermittlung, Kauf und Verkauf von Waren usw., die einen ständigen Strom von Ereignissen liefern. Nach einem anfänglichen Versuch, die Daten auf Redshift zu replizieren, kam man schnell zu dem Schluss, dass die Leistungsoptimierung und die Schemapflege sehr zeit- und ressourcenaufwändig sein würden. Depop entschied sich daraufhin, Amazon S3 als Data Lake zu nutzen. Quellen zu den Artikeln.
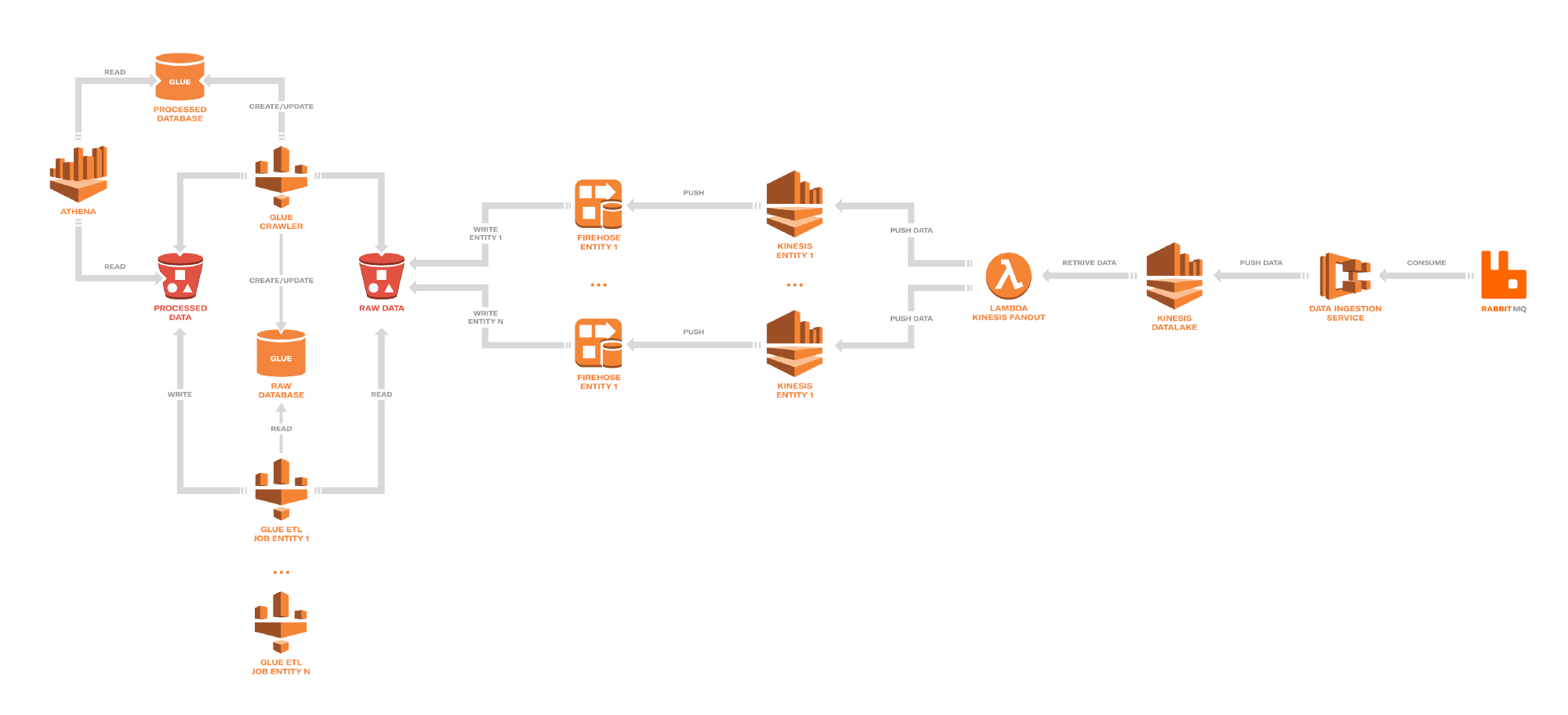
Beispiel für einen Depop Data Lake
Depop Data Lake Zusammensetzung:
Ingest - > Fanout - > Transform
Categories
Share


Benötigen Sie einen Projektkostenvoranschlag?
Schreiben Sie uns, und wir bieten Ihnen eine qualifizierte Beratung.